深入 Kafka Core 的设计(基础理论篇)
本篇主要围绕一致性副本复制协议、消息格式演进、消息落地上天以及其他细节的设计展开。
术语定义
| 名词 | 解释 |
| Broker | 又称 Kafka Server,是最基础的角色 |
| Controller | 一个 Broker 中活跃着 ZK 元数据管理服务的角色 |
| Consumer Group Coordinator |
一个 Broker 中活跃着消费组元数据管理服务的角色 |
| Consumer Group Leader/Follower | 是消费者内部角色,Leader 负责分配组内消费者成员消费的目标分区 ID |
| Record | 用户消息内容,可包含 Key、Value 与消息头 |
| Topic | 相当于数据库的一张表,索引关键字是 Offset,指向用户消息内容 Record |
| Compacted Topic | 一种特殊的 Topic 类型,可以丢弃相同 Key 字段的历史版本(Key 不能为空) |
| Leader Replica | 是 Topic 的某一分区主副本,负责对外提供生产或消费服务 |
| InSync Replicas (ISRs) | 是 Topic 的某一分区的活跃的处于同步状态的主从副本集合 |
| Log End Offset (LEO) | 某一 Broker 中的某一 Topic 的末端日志偏移量 |
| High Watermark (HW) | HW 表示 ISR 集合同步的进度,ISRs 的最小 LEO,也就是木桶的最短板 |
| Leader Epoch | 标记主副本的 Epoch,与 HW 保障了数据一致性 |
HW、LEO 与 ISR 的关系,注意的是,消费者提交的 Offset 与 LEO、HW 这种 Offset 值表示的是消息数据端点(边界),比如图中 Broker 101 的 Committed=HW=5,LEO=6;而消息内容的 Offset 值指的是数据段,比如图中 Broker 101 的消息内容 Offset=5 指的是末尾的消息。
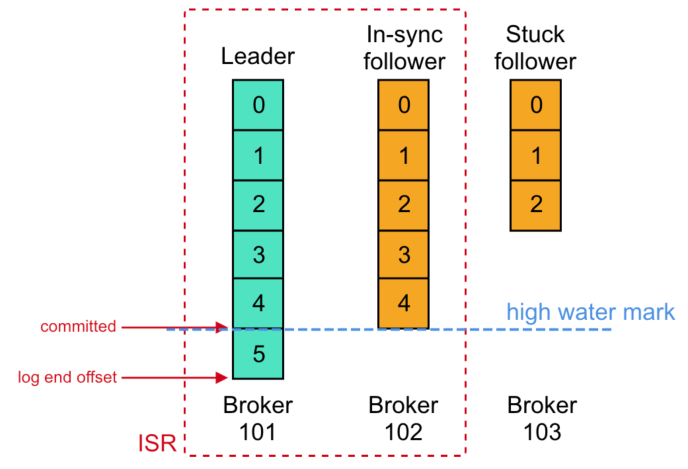
副本同步与 HW、LEO 的推进关系,
- 阶段一,从副本以本地 LEO 作为
fetch_offset拉取起始偏移量,请求主副本数据 - 阶段二,主副本得知从副本 LEO,从本地读取 LEO 起始的日志集合
record_set,更新remoteReplicasMap中的从副本 LEO,并尝试推进HW,完成后返回record_set与HW - 阶段三,从副本同步日志集合,推进本地
HW,回到阶段一
副本同步与 ISR 列表的扩缩关系,
- 当从副本 Broker 没有在
replica.lag.time.max.ms=30s发起拉取请求,则从主副本的 ISR 列表中移除 - 当不处于 ISR 列表的从副本,其 LEO 追上了主副本的 HW,则将由主副本 Broker 执行扩充 ISR 列表

Controller,是为了避免分布式事务协调问题,直接把元数据(如 Topic 管理)放在单节点单线程上运行;Active Controller 在 ZK 模式下是靠抢占 /controller 结点选出,而在 KRaft 模式下,根据 Raft 协议选出 Active Controller,并且依赖 Raft 协议同步操作日志与状态。
Consumer Group Coordinator,是为了管理消费组元数据,并持久化到 __consumer_offsets Topic。消费组成员所有 Offset 提交及成员变更的操作日志,都是提交给对应 分区 ID = hashCode(消费组 ID) % __consumer_offsets 的分区数 的主副本 Broker,并称之为该消费组的 Group Coordinator。
因此,所有 __consumer_offsets Topic 的主副本 Broker,就是所有的 Group Coordinator 集合。
安全提交论证
只有在 acks=all,Kafka 才满足 PacificA 分布式一致性框架模型,HW 作为用于判断第 X 个消息已安全提交的标记(严格的说类型为偏移量的 HW,标志着从 0 偏移量到 HW 偏移量的内容数据已经极大概率地安全提交 )。
因此在故障恢复时,Kafka 是没有针对主副本的选举机制的,而已知在 acks=all 条件前提下,满足 LEO >= HW 的就是 ISR 集合,因此,Kafka 可以直接从 ISRs 中任意选取从副本。
但现实并非如此简单,在副本切换中,处于 HW 之后的日志存在日志分叉,需要日志截断(试想一下为什么),这直接导致了某些情况下,即便在 HW 之前的消息也不能安全提交,Kafka 社区的 KIP-101 与 KIP-279 描述了其中的问题并引入 Leader Epoch 尝试修补日志截断的逻辑漏洞,但依然无法解决严谨的安全提交。
问题一,日志截断后立即成为主副本,导致日志丢失或分叉
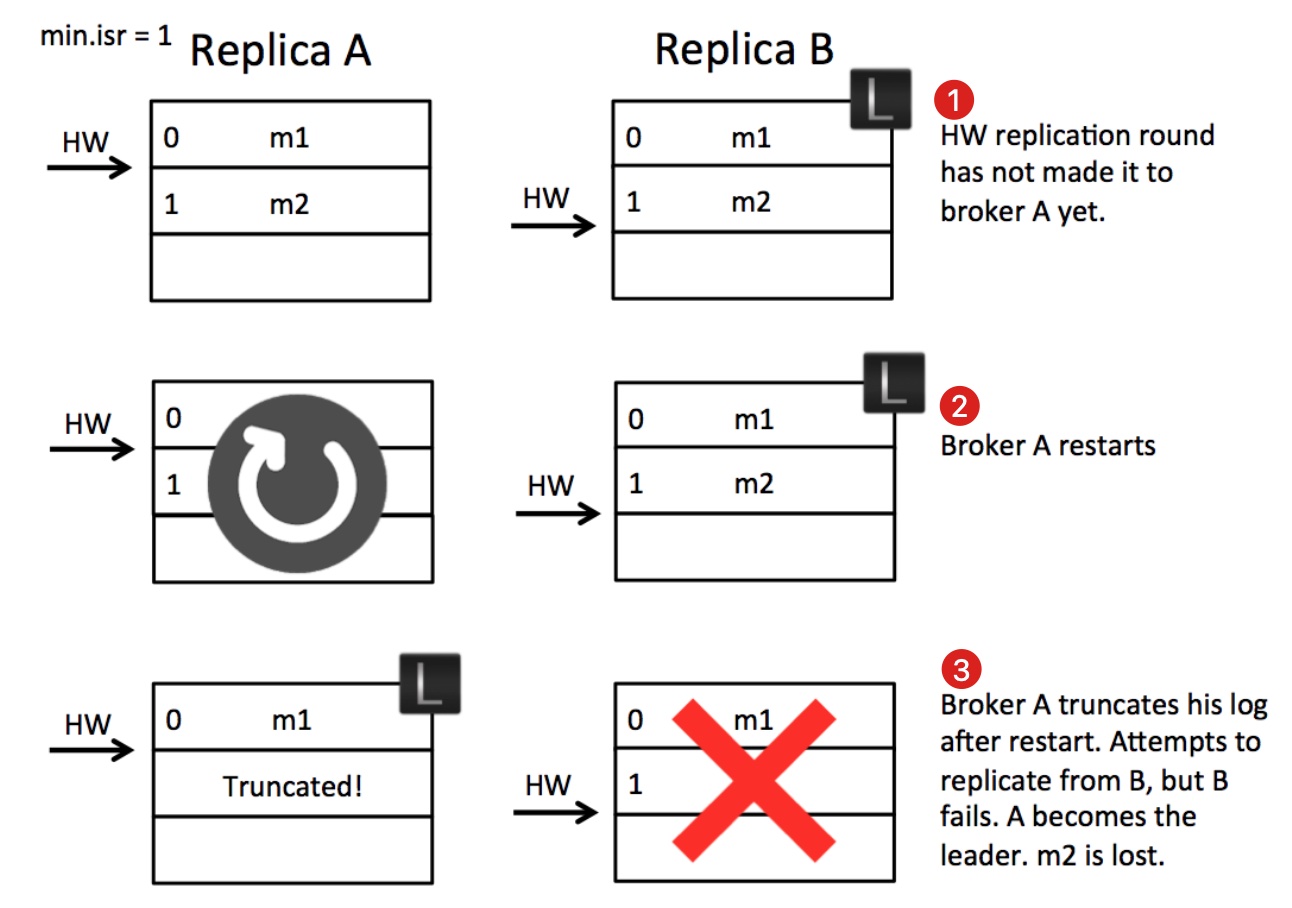
- 时刻一,B 作为主副本,由于 A 在此之前已拉取 m2 消息,并已告知 B,因此,此刻 B 推进(更新) HW=2,但 B 尚未返回告知 A 推进 HW=2 的回应
- 时刻二,A 处于重启,B 告知 A 推进 HW=2 的回应超时被丢弃
- 时刻三,A 重启执行日志截断,并尝试请求 B 拉取消息,但此刻 B 刚好崩溃,A 成为主副本,m2 被截断
- 最终,当 B 恢复时可能发生日志截断(因 A 告知 B: HW=1,B 执行日志截断),也可能因 A 被追加新的 m3 消息,发生日志分叉
问题二,多次硬件故障的重启,导致日志分叉
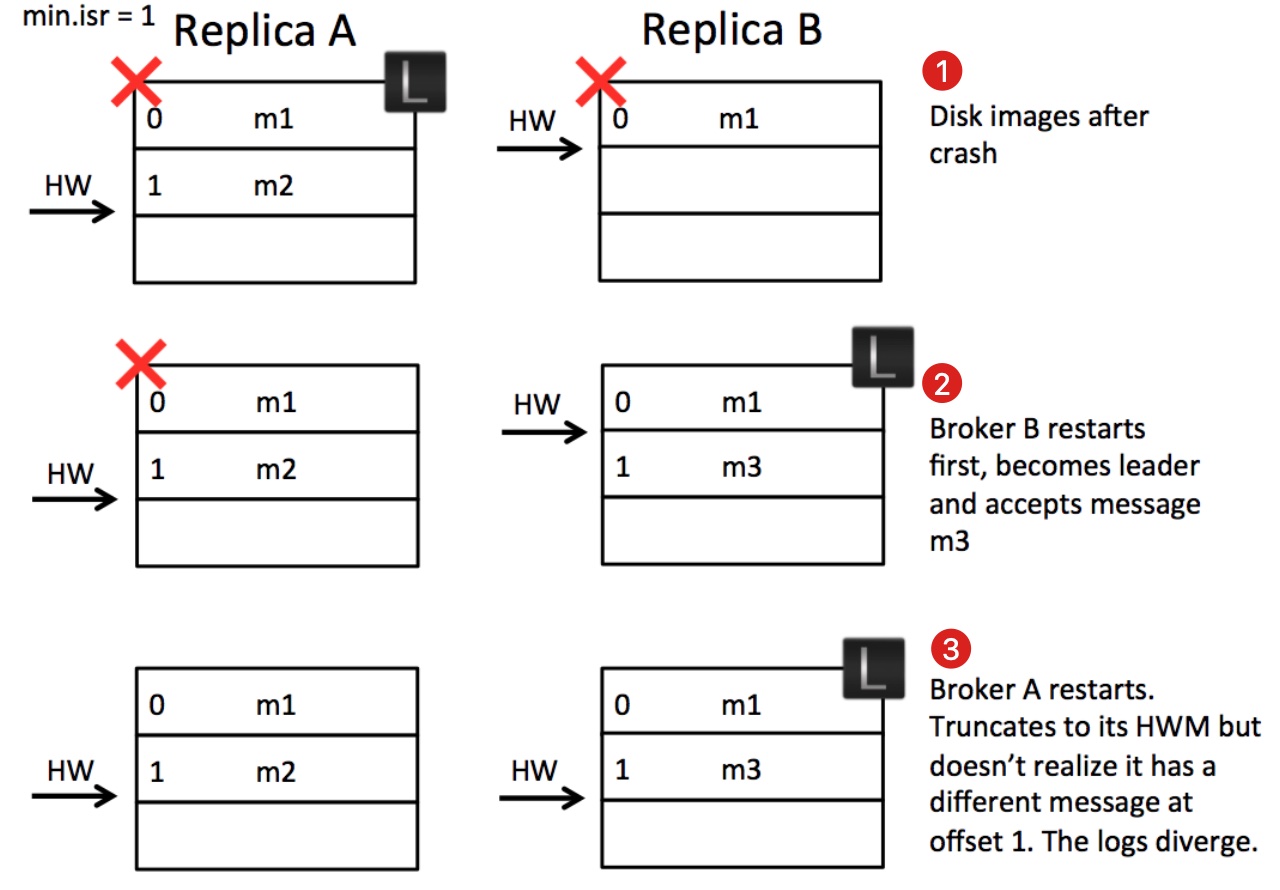
- 时刻一,A 作为主副本,A 在此之前已经得到 B 拉取 m2 消息完成的通知,A 完成推进 HW=2,此时 AB 崩溃,但是由于 B 异步刷写磁盘,在崩溃时,并未写入 m2 消息
- 时刻二,B 重启恢复完成,成为主副本并接受到 m3 消息
- 时刻三,A 重启恢复完成 ,由于 AB 均 HW=2,A 无法意识到 Offset=1 的旧消息与 B 的新消息不一致,导致 AB 日志分叉
解决办法其实很简单,根本问题就是从副本在日志截断之前,没有与主副本同步状态,然后主副本一旦崩溃,从副本的数据就和主副本的不一致。
Leader Epoch 的解决办法是,记录 [LeaderEpoch => StartOffset] 向量,在从副本的 Broker 重启时,向主副本的 Broker 发起最近的 Epoch 的 LeaderEpochRequest 请求,得到最近的 Epoch 在目前主副本上 LEO,然后从 LEO 开始截断从副本的日志,这样就保证了从副本的 Broker 在旧的至最近的 Epoch 上数据保持一致,然后再增量拉取新 Epoch 的日志(Epoch 相当于一个栅栏)。
针对问题一,

- 时刻一,B 作为主副本,由于 A 在此之前已拉取 m2 消息,并已告知 B,因此,此刻 B 推进(更新) HW=2,但 B 尚未返回告知 A 推进 HW=2 的回应(和之前问题一的时刻一,相同)
- 时刻二,A 重启完成后,向 B 发起 LeaderEpochRequest 请求,由于 A 最近的 LeaderEpoch=0,B 返回 LE0 的 LEO=2,由于 A 当前的 LE 符合 B 返回的,且 LEO 相等,则无需进行日志截断
- 时刻三,B 崩溃,A 成为主副本,更新
leader-epoch-checkpoint快照文件(图中 LG 与 Offset 对的部分),其第二行代表着在 LE=1 时,StartOffset=2,即 LE=0 时,LEO=2,使用快照文件可便于回溯过去 Epoch 的 LEO - 结论,可以见得 m2 消息得到保留,说明主副本的 HW 之前的数据可以在这种情况被认为安全提交
针对问题二,
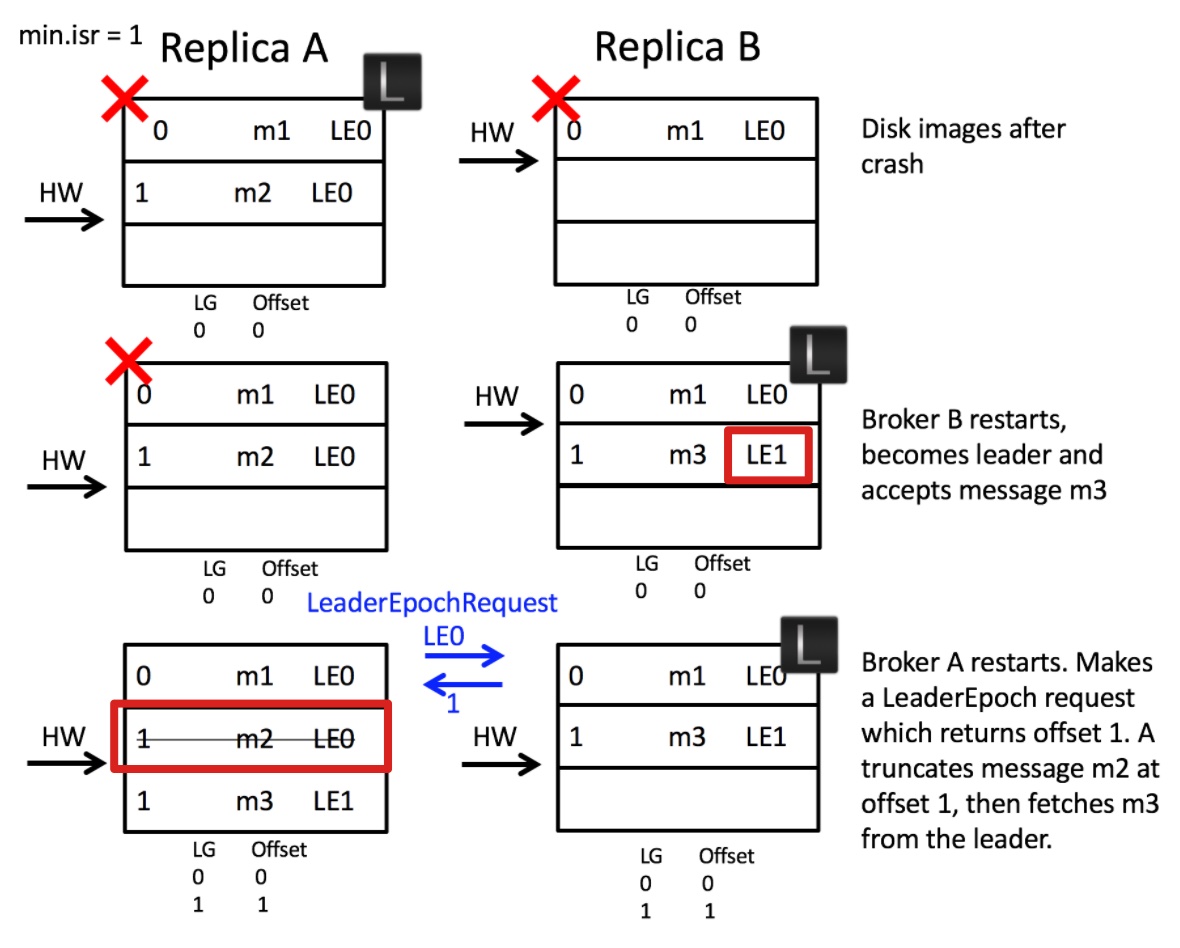
- 时刻一,A 作为主副本,A 在此之前已经得到 B 拉取 m2 消息完成的通知,A 完成推进 HW=2,此时 AB 崩溃,但是由于 B 异步刷写磁盘,在崩溃时,并未写入 m2 消息(和之前问题二的时刻一,相同)
- 时刻二,B 重启恢复完成,成为主副本并接受到 m3 消息,并且更新
leader-epoch-checkpoint快照文件(图中遗漏了,可参考时刻三的 LG 与 Offset 对的部分) - 时刻三,A 重启恢复完成 ,A 向 B 发起 LeaderEpochRequest 请求,由于 A 最近的 LeaderEpoch=0,B 返回 LE0 的 LEO=1,A 执行日志截断至 LEO=1,m2 消息被删除,在随后,A 拉取 m3 信息并更新其
leader-epoch-checkpoint快照文件 - 结论一,此例子说明异步刷写磁盘的情况下,主副本的 HW 之前的数据不能认为安全提交,也有可能会丢失(但实际上,从副本不能保证提交时同步刷写到磁盘完成,数据丢失应该是必然的)
- 结论二,事实上,可以看出这个问题出现于 ISRs 全部崩溃,然后缺失数据的从副本(即 B 副本)恢复速度更快,导致 B 成为主副本并接受新的消息导致的,所以只要保证 ISRs 全部崩溃的概率足够小,即可认为安全提交,或者增大
min.insync.replica值,这样可以确保恢复时,选出的主副本就不是在崩溃中可能丢失数据的 Broker(可以试想为什么)
另外,由于消费者与从副本同步类似,于是 KIP-320 把 LeaderEpoch 设计推广到消费者,抛出 LogTruncationException 异常使得消费者感知到日志截断,从而采取进一步行动,比如外部程序可以从上一次全局快照点(比如 Flink 的全局一致性快照)的 Offset 信息,通过 seek API 回滚重新消费数据。
消息格式演进
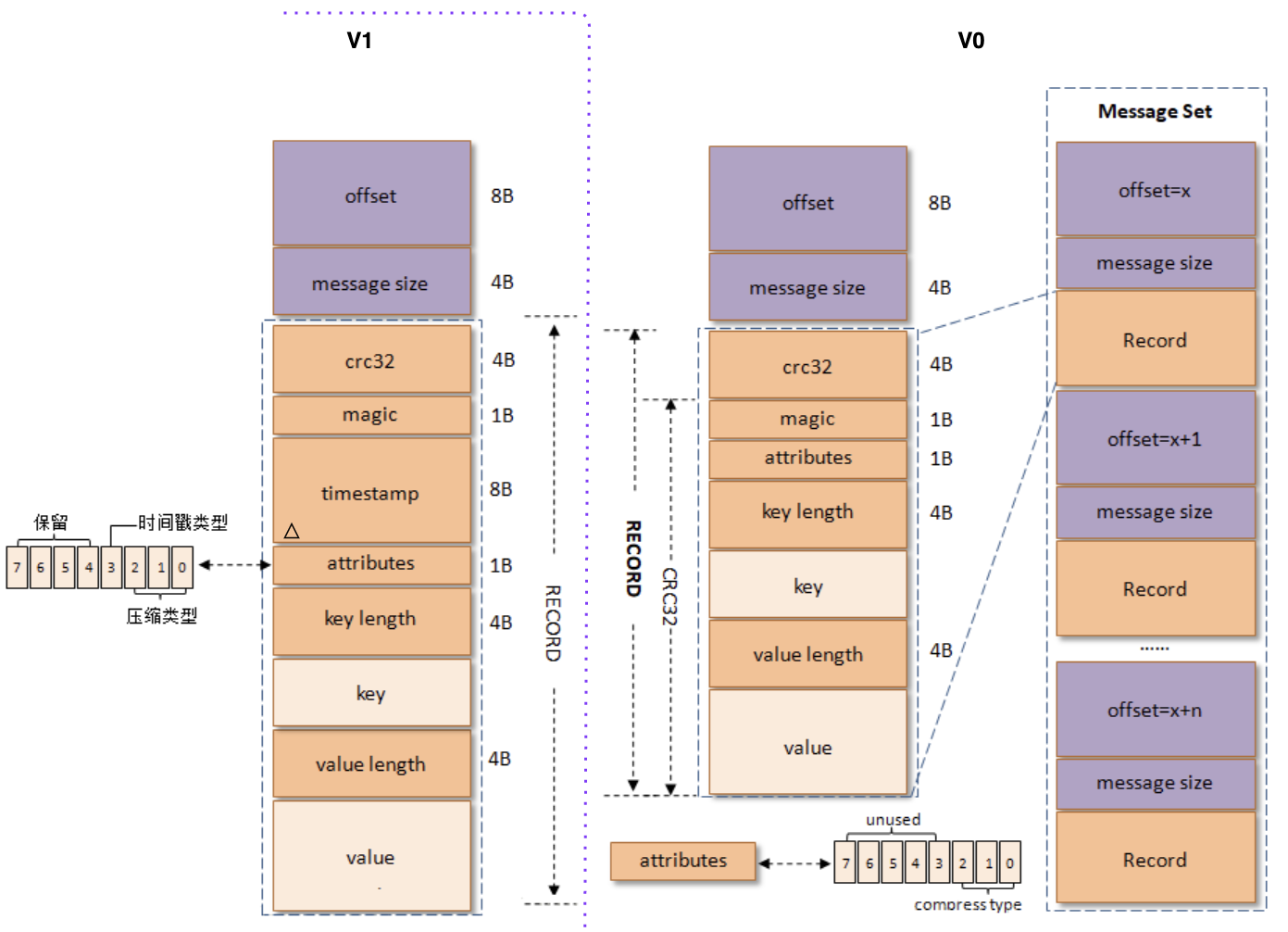
V0、V1 格式
历史悠远的消息格式,V1 在 V0 基础上增加时间戳字段。另外,在新版的 Kafka 2.8.0 中,V0 与 V1 消息集 MessageSet 已经更名为 LegacyRecordBatch,图中外侧的,Record 单元更名为 LegacyRecord。
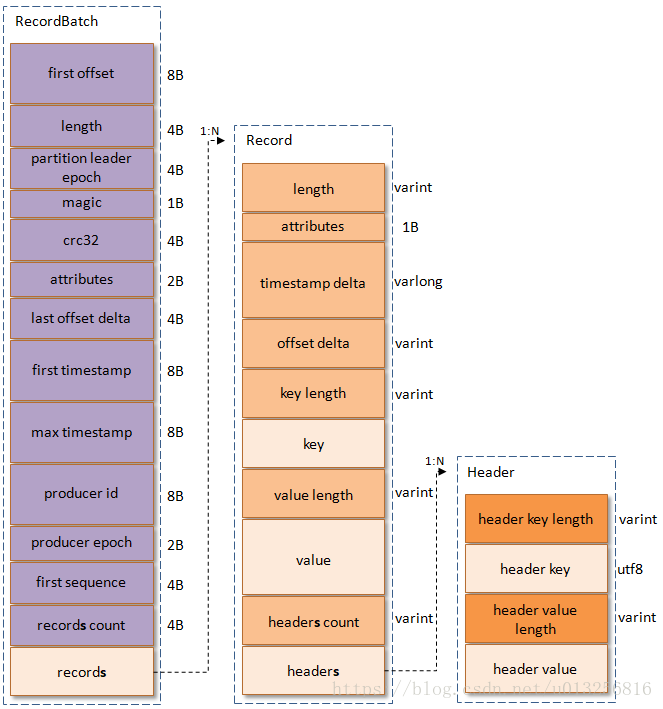
V2 格式
17年中旬发布的格式,小修小补沿用至今。
主要区别就是增加协议头信息的 First Offset 与 Last Offset Delta(便于压缩格式消息的落盘),其次是 Record 字段大量使用可变长度整数记录长度、时间戳也是增量编码、Record 增加消息头字段,其次是把 CRC 从旧版的每条 Record 中拉到协议头上。
消息落地与上天
仅考虑 V2 格式消息。
落地
- 无论是主副本还是从副本的落地,写入最终都交由 Log 对象,Log 对象首先反序列化 ByteBuffer,得出消息格式 RecordBatch(对应下图中的
RecordBatchIterator解析ByteBufferLogInputStream) - 进行消息校验与计算真实的 FirstOffset、LastOffset 与时间戳(但仅针对消息的时间戳类型是 LogAppendTime 类型)
- 交由 LogSegment(Log 是分区整体处理的模型,LogSegment 是分段日志管理的模型) 关联的 FileRecords 写磁盘,磁盘上消息日志文件名规则是
${baseOffset}.log,当日志需要滚动时,就会以准备写磁盘的 FirstOffset 作为文件名,即 RecordBatch 的第一条消息的 Offset 作为文件名 - 最终以当前写入的文件的大小作为偏移量对应索引的值域,更新 OffsetIndex 与 TimeIndex 索引数据
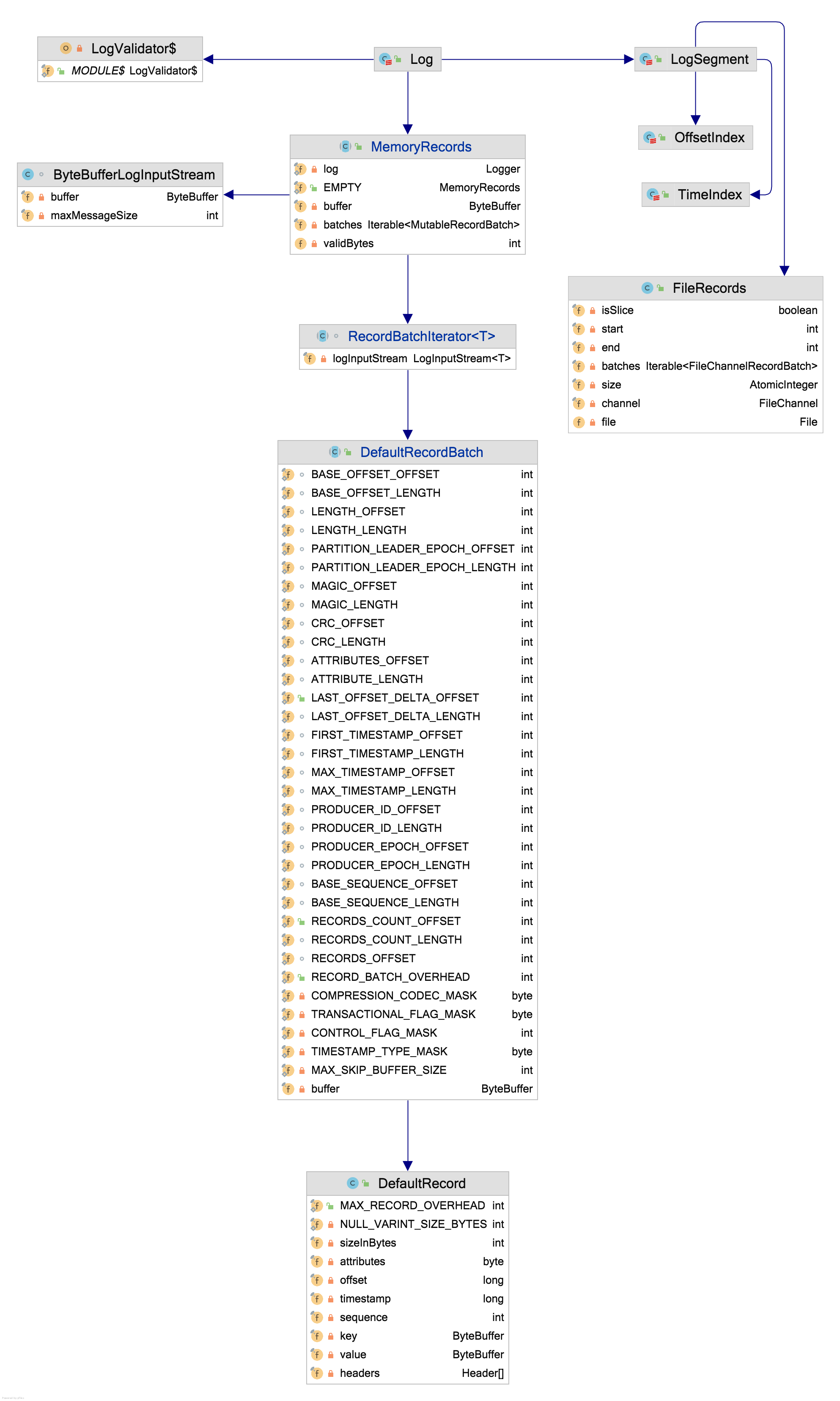
值得注意的是,LogSegment 的所有写入(也就是 FileRecords、OffsetIndex 与 TimeIndex 的写入)其实是异步刷盘的,虽然提供 kafka-log-flusher 服务,但是默认并没有启用,Kafka 希望通过多副本的高可用替代强制刷写功能。
还有,也别忘记当某分区刚成为主副本,第一次消息写入时还需要处理 LeaderEpoch 特性,即更新 leader-epoch-checkpoint 快照。
另外,生产者开启的压缩,是批量压缩的。由于主副本的 Broker 端依旧需要进行消息校验与赋予 RecordBatch 的 LastOffset、时间戳,所以主副本无可避免的需要解压缩。
上天
一般场景,通过 Offset 读取消息,Log 对象首先根据磁盘的文件名(实际上这些日志与索引文件的信息都在内存中),找到 baseOffset <= targetOffset 的索引文件,然后 translateOffset 把 targetOffset 转换为日志文件的实际位置,然后根据 max.partition.fetch.bytes=1M 参数直接返回磁盘对应大小数据的起点与终点位置,并把起点与终点传递给新创建的 FileRecords 对象,最终通过其 writeTo 方法调用 FileChannel#transferTo 直接往对应 epoll 的 Socket 描述符写出圈选的数据。(即 ZeroCopy 的实现,但前提是 PLAINTEXT 或者包含用户名密码认证的纯文本 SASL_PLAINTEXT)
public long writeTo(TransferableChannel destChannel, long offset, int length) {
int oldSize = sizeInBytes();
long position = start + offset; // offset 是标记 epoll 断断续续写的进度
long count = Math.min(length, oldSize - offset);
return destChannel.transferFrom(channel, position, count);
}日志删除
日志清理在代码中其实分为两种服务,一种叫日志删除服务,一种叫日志清理服务。但一般场景,比较经常遇到的是,需要对非 Compacted Topic 的日志清理,也就是日志删除服务。
// 服务于非 Compacted Topic
info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs))
scheduler.schedule("kafka-log-retention",
cleanupLogs _,
delay = InitialTaskDelayMs,
period = retentionCheckMs,
TimeUnit.MILLISECONDS)// 服务于 Compacted Topic
if (cleanerConfig.enableCleaner) {
_cleaner = new LogCleaner(cleanerConfig, liveLogDirs, currentLogs, logDirFailureChannel, time = time)
_cleaner.startup()
}日志删除分为三种情况:超过保留时间、超过保留大小、用户指定起始保留的 Offset(即推进 logStartOffset),分别通过取 TimeIndex 的最后一条数据、计算累计文件大小、删除 baseOffset 小于 logStartOffset 的日志及其索引。
限时任务与层级时间轮
Delayed Operation
Kafka 所有限时任务都继承自 DelayedOperation,如有:
- DelayedFetch,当前的拉取数据量不足以满足
replica.fetch.min.bytes=1,那么会把拉取操作延迟fetch.max.wait.ms=500ms - DelayedElectLeader,执行
kafka-leader-election.sh对分区进行新选举时,Controller 异步统计结果 - DelayedJoin,延迟以等待所有消费者都加入消费组
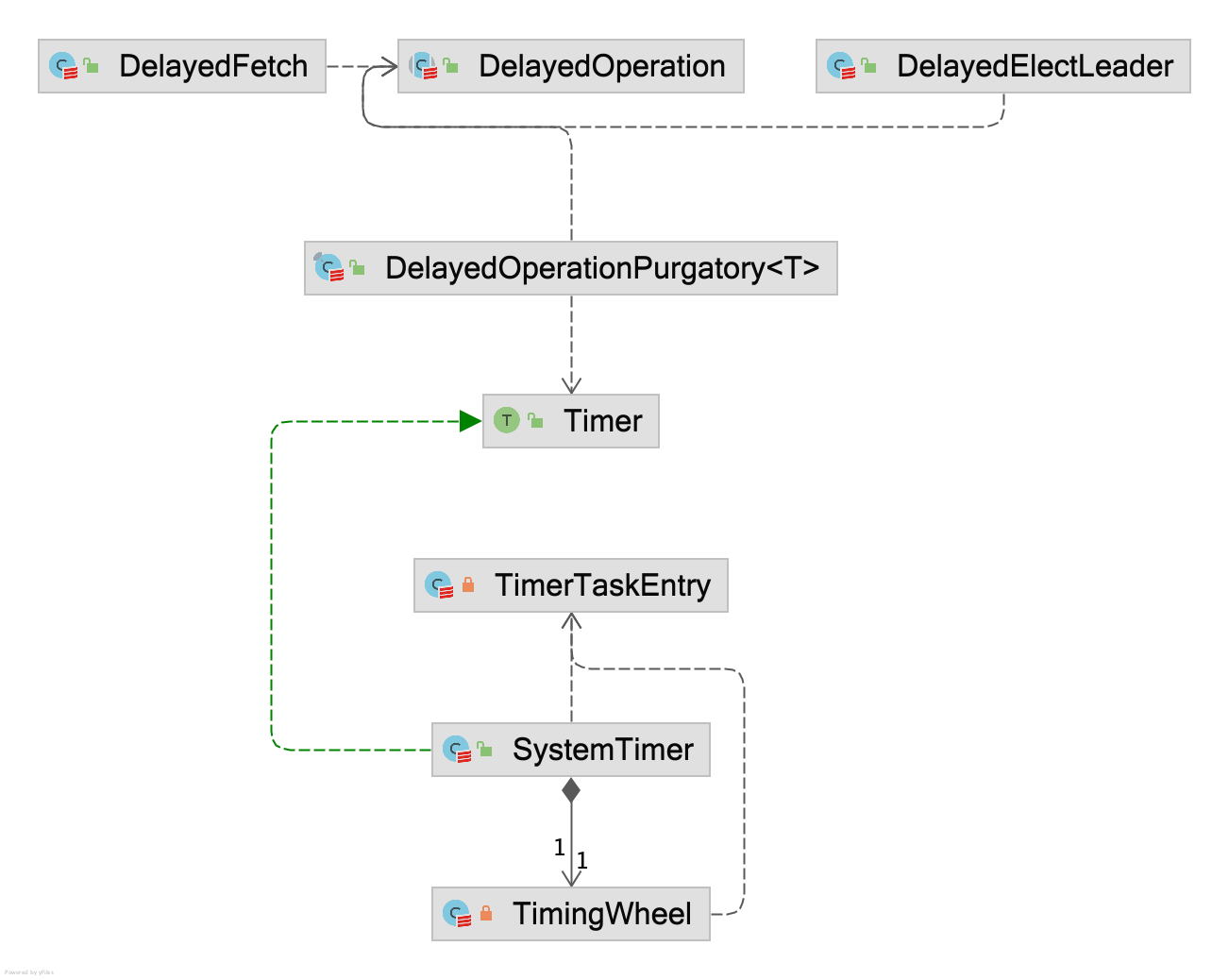
但 DelayedOperation 只是描述任务信息,负责调度与索引任务数据的是 DelayedOperationPurgatory(Purgatory aka. Heaven’s Waiting Room 炼狱是去往天堂的候车室),主要提供索引任务(比如某任务可以提前结束,那么就需要索引到其任务,并标记完成;不过其使用 ConcurrentHashMap + 内部实现的分段锁,不明确此优化的性能),以及把任务注册到定时器上,Kafka 在这里使用比较有趣的数据结构 Hierarchical Timing Wheels 层级时间轮。
Hierarchical Timing Wheels
Hierarchical Timing Wheels 层级时间轮,相比较 java.util.concurrent.DelayQueue 的设计,后者采用优先队列实现,按照限期时间排序,比对优先队列的堆顶与现实时间之差,判断是否任务到期;前者渴望通过较粗粒度的限期,在同粒度的限期任务无需进入优先队列,而是通过索引找到优先队列的粗粒度的限期任务集合(实现上被称为桶,不同的桶定时的精度不一样,且桶内的任务不能切换到别的桶),但最终还是依赖 DelayQueue 对桶级别进行限期,而非对任务的定时(即桶的定时到期,桶内的所有任务列表认为到期)。
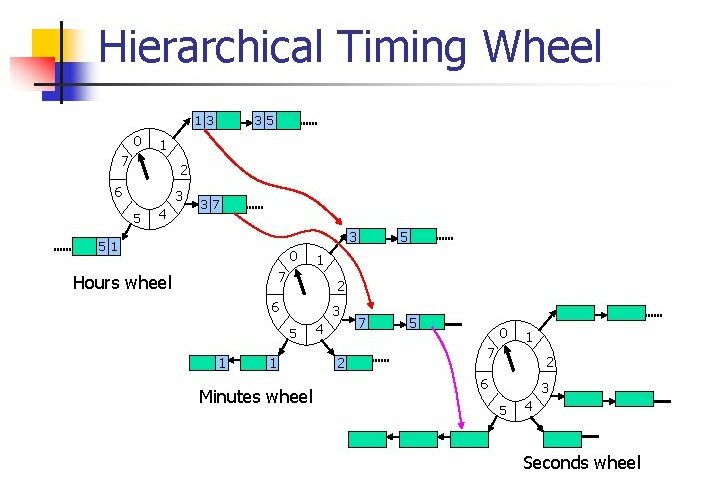
本质上,使用 HashMap 分解定时的粒度也可以,比如定时的是未来 50ms 以下完成的放入第一号任务列表,未来 200ms 以下完成的放入第二号任务列表,每 50ms 推进一格,即一号队列清空,而二号队列含义变成未来 150ms 以下完成的放入第二号队列,以此类推。
层级时间轮分层,在默认配置下,其粒度可以描述成:
| 层级 | 每层桶的数量 | 起始 | 结束 | 粒度 |
| 第一层 | 20 | 1ms | 19ms | 1ms |
| 第二层 | 20 | 20ms | 399ms | 20ms |
| 第三层 | 20 | 400ms | 7999ms | 400ms |
举个例子,现在有 100ms 的任务需要定时,它将会放入第二层的第五号桶,此时桶是空的,会使用 DelayQueue 定时 100ms,然后过了 30ms 后,有 80ms 的任务需要定时,它也会放入第二层的第五号桶,再经过 70ms 后,DelayQueue 定时完成,桶的所有任务将被执行。例子中,其实含义就是 100ms 与 110 ms 放在同一定时的粒度的 DelayQueue。
参考资料
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-101+-+Alter+Replication+Protocol+to+use+Leader+Epoch+rather+than+High+Watermark+for+Truncation
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-279%3A+Fix+log+divergence+between+leader+and+follower+after+fast+leader+fail+over
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-320%3A+Allow+fetchers+to+detect+and+handle+log+truncation
- https://lrita.github.io/2020/02/10/pacific-a-framework/
- https://t1mek1ller.github.io/2020/02/15/kafka-leader-epoch/
- https://stackoverflow.com/questions/39203215/kafka-difference-between-log-end-offsetleo-vs-high-watermarkhw
- https://www.cnblogs.com/huxi2b/p/5903354.html
- https://honeypps.com/mq/kafka-log-format-evolution/
- https://github.com/lvyong1985/note/issues/28
- https://docs.confluent.io/platform/current/installation/configuration/broker-configs.html
- https://juejin.cn/post/6844904049628676104