Google Mesa 项目论文笔记
Google Mesa 是指标分析型数据仓库,主要服务于 Google AD 业务。本文抽离自 Apache Doris 的研究笔记,因此仅记录了论文中核心设计部分,省略了前置背景说明以及没有太关注的地方,原始全文是Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing。
存储结构
版本管理
- 定义 $deltas$ 为数据存储的一系列物理文件,每个 $delta$ 中包含数据行和以 $\rm [V1, V2]$ 形式描述的版本号,代表着该 $delta$ 是从 $\rm V1 \sim V2$ 版本的指标列聚合结果;
- 定义 $singleton \ delta$ (简称 $singleton$)为版本号形如 $\rm [V1, V1]$,代表着该 $singleton$ 记录的是 $\rm V1$ 单版本的未被聚合的明细数据。
- 对于 Mesa,仅提供查询当天明细(原文表述方式是 24 小时内用户可以查询特定的版本),24 小时之前只能查询聚合结果,因此 Google 给出其独特的 Compaction 实现,
- Base Compaction,实施合并的周期是每一天,其合并后的版本号从 0 开始。
- Cumulative Compaction,每更新 10 版本进行增量构建。
- 分析可得,
- 在查询历史聚合结果时,只需查询 1 份 Base Compaction 的 $delta$ 、1 份 Cumulative Compaction 的 $delta$ 以及最多不超过 10 份的 $singletons$。
- 在查询当天明细结果时,只需返回当天特定版本的 $singletons$ 中的明细数据即可。

前缀索引
- 在记录数据的同时,同时写入名为 $short \ key$ 的前缀索引,索引键取自固定长度的前缀。
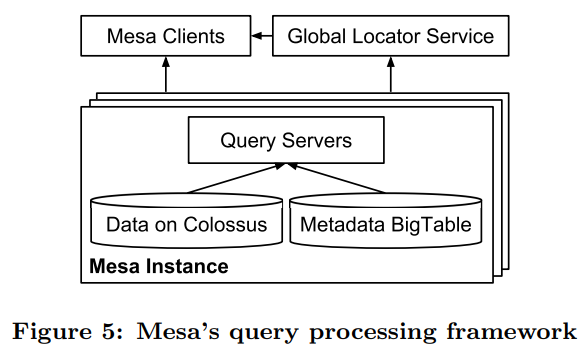
系统架构
单实例模型
每个 Mesa 实例由两个子系统组成,更新&维护子系统、查询子系统。
- 更新与维护子系统,用于保障当前实例数据的版本更新、查询优化等功能,采用 Controller 与 Workers 架构,物理数据存储在 Google 新一代文件系统 Colossus 上(相当于 S3,据有限的资料显示是基于 BigTable 实现元数据存储,而物理数据则被优化地存储在 GFS)。

- 查询子系统,不支持 Join。
- 把相似的查询请求(比如查询同一张表),发送到同一组查询服务器,以提高缓存命中率。
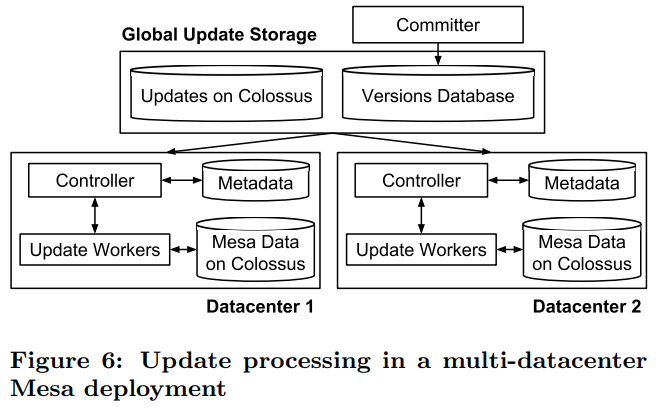
跨数据中心多实例模型
在单实例的背景下,增加了两个部件,Committer 版本提交器角色与像 ZK 一样的 Versions Database 版本信息数据库,通过控制版本的可见性以实现一致性更新,这个方法也同样适用于,一张表中有多物化视图时,相关联表的更新一致性控制。
高级特性
查询优化
- 非前缀键的查询,由于索引行包含多个键,利用集合关系在扫描时排除不包含的页
- 在查询时使用 $resume \ key$,当查询服务器 Fault 的时候可以继续从上次中断处恢复
Workers 并行化
Workers 是更新与维护子系统的执行节点,执行 Compaction、表结构变更、数据校验任务,这些任务的共性都是依赖顺序扫描,然后形成一份新的全量数据,于是借鉴 MapReduce 思想,分解任务,再分配给 Workers 集合。
这里有一个困难点 —— 如何平均分配每个 Worker 任务的分区范围?
方法是基于采样,
- 定义 $n$ 为某一任务所需扫描的总行数(总任务量)
- 定义 $m$ 为某一任务中关联的 $deltas$ 文件集
- 定义 $p$ 是期望的分区数(并行度)
- 定义 $s$ 为采样密度(缩放倍率),比如 $s = 1024$,代表采集每 1024 的整倍数行
理想情况下,每个分区扫描的行数应为 $n/p$,但这需要一次全量顺序扫描以决定分区键。
采样的方法是,假设 $s=1024$,只需要对 $m$ 集合的每个 $delta$ 文件,单点查询第 $[0, 1024, ..]$ 行,构建 <行键,权重> 映射(权重 = s * 此行键出现次数,理想情况下,总权重 = 总行数 n),通过行集的键排序,辅以权重,可计算出分区键。
并且可计算得最坏情况是,一个键在采样时,只出现 1 次,但事实上,每个 $deltas$ 内部都重复了 $s$ 行(但不会超过 $s$ 行,因为超过必然会被采集到),也就是错误量被限定为 $(m-1)s$,因此,单分区最大扫描行数是理想情况与错误量之和,即 $(n/p)+(m-1)s$。
由于通常 $m$ 在现实上会控制得非常小(为了查询速度),所以 $s$ 可以非常大,因此在该 MapReduce 任务启动时的准备工作的耗时也是非常短的。
另外,由于并行化,每个 Reducer 将写出单独的一份文件,因此,合并过程并不会像 HBase 那样只生成一份文件,而是生成全局有序的多份文件,在点查时二分。实际上,在 Apache Doris 也是如此设计,但未实现 Worker 并行化。
快速在线的表结构变更
在 Mesa 中,表结构变更的首要需求是在线,即,操作不能阻塞用户的所有查询或更新。
一个常规的方法是,
- 创建表的副本,并赋予新的版本号
- 重放(Replay)创建副本时的更新操作
- 切换读写到新表,即修改 Mesa 元数据,把操作路由到新表
另一种更快速的方法 $Linked \ Schema \ Change$,但论文中并没有说具体实现,大致想法是把表结构变更变成一种可合并的更新操作,在查询时,根据新的表结构对新增的列填充默认值返回结果。(根据这个想法,或许可以直接添加转换层,对旧版的 $deltas$ 通过转换层的映射函数实现表结构变更)
数据一致性检测
由于 Mesa 通常是多数据中心多实例部署,如何比对多实例的数据一致性就成了核心问题。
论文中提出两种方法,分别是全面的离线检测方法与轻量级检测方法,
- 全面的离线检测方法
- 基于行序依赖的强一致性检测(Strong Row-order-dependent Checksum)
它是hash( hash( hash( row1 ) + row2 ) + row3 )..结构,
在每次求校验码的时候传入上一行求得的校验码,因此得到行序依赖的校验码。 - 基于索引的行序无关的弱一致性检测(Weak Row-order-independent Checksum)
仅用于检测索引,由于行序无关,文中无详细记载,可能是索引抽样比对。
- 基于行序依赖的强一致性检测(Strong Row-order-dependent Checksum)
- 轻量级检测方法
- 基于元数据中聚合值的一致性检测(Global Aggregate Value Checker)
仅用于检测上一次更新的数据,通过对比 $delta$ 文件中元数据的聚合值判断一致性。
(原文并没有展开说聚合值包含什么,但大概猜测是行数、最大最小值之类的)
- 基于元数据中聚合值的一致性检测(Global Aggregate Value Checker)
其他的,像单实例内部的有序性检测(比如刷写磁盘之前数据是否有序)、损坏的数据可以从不同实例中拷贝恢复的特性就不说了,它们都是显而易见的。