拖更中: 来分析分析多维分析系统 Doris
目前可能并不那么好用,但无碍它是一个设计精妙的 OLAP 系统。
基本背景
| 名词 | 解释 |
| FE | Frontend 角色,提供 SQL 解析与调度 |
| BE | Backend 角色,提供计算与存储 |
| Broker | 通过 Broker 隐藏访问远程文件系统(主要是 HDFS、S3)的具体实现细节 |
| Tablet | 一张表的分片,分片数量由分区与分桶数的乘积决定 |
| Rowset | 一次新的导入可理解为记录新版本的数据,Rowset 指代某范围版本的数据 |
| Segment | 物理数据段文件。一个 Rowset 的 Segments,其之间有区间重叠与否两种情况 |
| Column | 一份数据段由表的所有列组成,并且是平铺的结构(见后文 Segment V2 设计) |
| Page | 64K 组成页,压缩解压缩的单位,也是 IO 读写一次的最小单元 |
| Block | 提示一下,fs::Block 指代文件系统的物理文件,否则,看代码时候可能会迷惑 |
| Base Compaction |
|
| Cumulative Compaction |
使用手册
导入
Broker Load
首先,尽量在建表时,把字段数据长度限制到准确范围。目前阶段 Broker Load 的内存管理并非依据实际数据长度进行分配,而是表结构中反映的单行字节长度进行内存分配,并直接影响控制 MemTable 内存表刷盘时机判断(默认策略是内存表达 write_buffer_size=200MB 时刷盘)的准确性。
其次,需要优化调整相关参数,分别有两种,
第一种是 BE 控制内存表刷盘时机:
- 配置在 be.conf 的,刷写文件速率限制
push_write_mbytes_per_sec,-1 表示不限速 - 配置在 be.conf 的,当一个 Tablet 的内存表的大小达
write_buffer_size,开始异步刷盘 - 配置在导入 SQL 的,当所有内存表的大小达
exec_mem_limit的 1/3 强制同步刷盘(TabletsChannel#reduce_mem_usage方法)
第二种是 BE 抽取与转换并行度:
- 配置在 fe.conf 的,集群最大转换线程数
max_broker_concurrency - 配置在导入 SQL 的,限制每个 BE 导入转换线程数的
load_parallelism - 计算导入任务的分片数,但目前暂不支持非纯文本的切割,因此分片数约等于文件数
因此,Broker Load 转换并行度,也就是实例数,可以近似描述为,
min( BE 实例数 * loadParallelism, maxBrokerConcurrency, fileNum )
导入 SQL 可参考,
LOAD LABEL psd.lbs_wide_di (
DATA INFILE ("hdfs://nameservice1/tmp/lbs_wide_di_20211226/*")
INTO TABLE lbs_wide_di
PARTITION (p_20211226)
FORMAT AS "parquet"
)
WITH BROKER "hdfs_broker"
PROPERTIES (
"exec_mem_limit" = "32212254720", -- 内存仅供参考
"load_parallelism" = "32", -- 控制单 BE 的 BrokerScanNode 数
"timeout" = "259200" -- 超时参数的上限,仅供参考
)代码实现备注,
- 切入点可参见 PlanFragmentExecutor#open_internal,其实现的逻辑就是,不断地从作为数据源的 BrokerScanNode#get_next 中获取 RowBatch 对象(数据抽取过程),然后传递 RowBatch 到 OlapTableSink#send 进行拆解 RowBatch,按照分区分桶规则重新组合,并镜像数据流到 Tablets 的所有副本(若存在多个物化视图,则会再次镜像数据流,发送到物化视图对应的 Tablets 的所有副本里),最终通过 PInternalService#tablet_writer_add_batch 的 RPC 调用把数据流汇合到所有的副本 BEs 中。
- 当其中一个副本 BE 接收到流入的数据后,通过 LoadChannel#add_batch 解析出要汇入的 Tablet,传递到对应 Tablet 的 DeltaWriter#write,把 RowBatch 转换为 Tuple,并插入到 Tablet 对应的 MemTable 内存表中,从此往后的过程,与 LSM 树结构的其他组件一样,跳表插入然后刷写磁盘。
Spark Load
太慢了
Stream Load
流的事务
查询
查询参数
parallel_fragment_exec_instance_num
storage_page_cache_limit
index_page_cache_percentage
doris_scanner_thread_pool_thread_num
max_compaction_threads物化视图
物化视图可实现多种前缀索引,但可能需要注意以下几点:
1. 建表报错
ERROR 1064 (HY000): errCode = 2, detailMessage = The partition and distributed columns uid must be key column in mv解决方法是在创建物化视图时,添加 order/group by index_col, 分桶键,比如:
CREATE MATERIALIZED VIEW lbs_wide_wi_for_wifi_idx_mat
AS
SELECT
wifi,
uid, -- 分桶键
app_key -- 分桶键
FROM lbs_wide_wi
GROUP BY wifi, uid, app_key; -- 用 GROUP BY 去重2. 用作二级索引查询
如果查询模式主要基于多维度查明细数据,直接使用物化视图记录所有列数据,数据膨胀率会变大很多, 使用二级索引无论是空间利用率还是查询性能都优于直接构建所有列数据的物化视图。另外,当前版本暂时不支持内部进行二级索引转换,即先从物化视图,查出前缀排序键,再从前缀排序键,查出所有列数据,所以临时解决方法可以通过 INNER JOIN 实现:
SELECT a.*
FROM lbs_wide_wi a
JOIN (
SELECT DISTINCT uid, app_key, wifi -- 筛出前缀索引键,通过去重命中物化视图
FROM lbs_wide_wi -- 右表足够小的话将会广播
) b ON a.uid = b.uid
AND a.app_key = b.app_key
AND a.wifi = b.wifi
WHERE b.wifi = "AC:B3:B5:73:A1:28";存储层设计
物理目录设计
/shard_id/xxx/xxx
Segment V2 设计
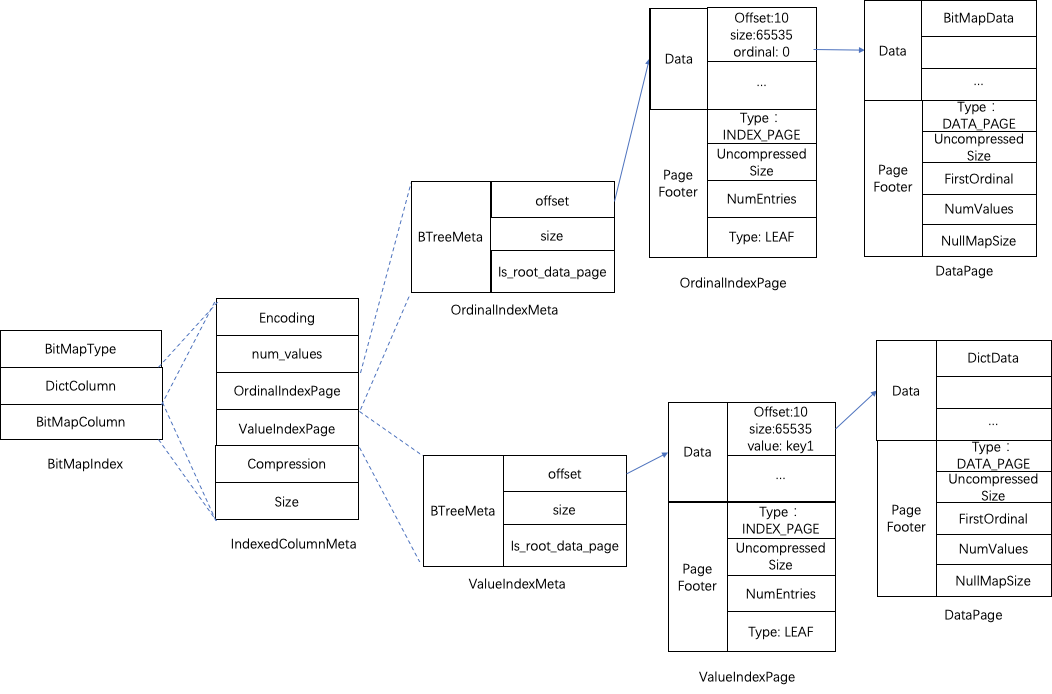
- Segment(物理数据段文件)

- Data Page(数据页)

- Ordinal Index(行号索引)
- 行号索引是针对 Segment 文件,此行号亦非表的真正行号,而是列式存储内部的行号。
- 后面所有索引都返回行号,然后汇总计算行号范围,最终查询本索引来读取数据页。
- 当数据页写满 64K 时,记录当前页的起始行号,形成行号与页偏移量的列表;读取时,通过行号查得页偏移量。另外还记录有,页 ID 与页偏移量的列表,辅助索引块状结构的 ZoneMap 索引、布隆过滤器及位图索引。
(比如:“查在第 1234 行的数据” => “对每一列,查得数据页偏移量与大小”) - PS. 正如下图 BTreeMeta 所示,本索引是由两层 B+ 树组成,即由根索引页与叶子结点数据页组成,根记录着指向叶子结点指针的列表。
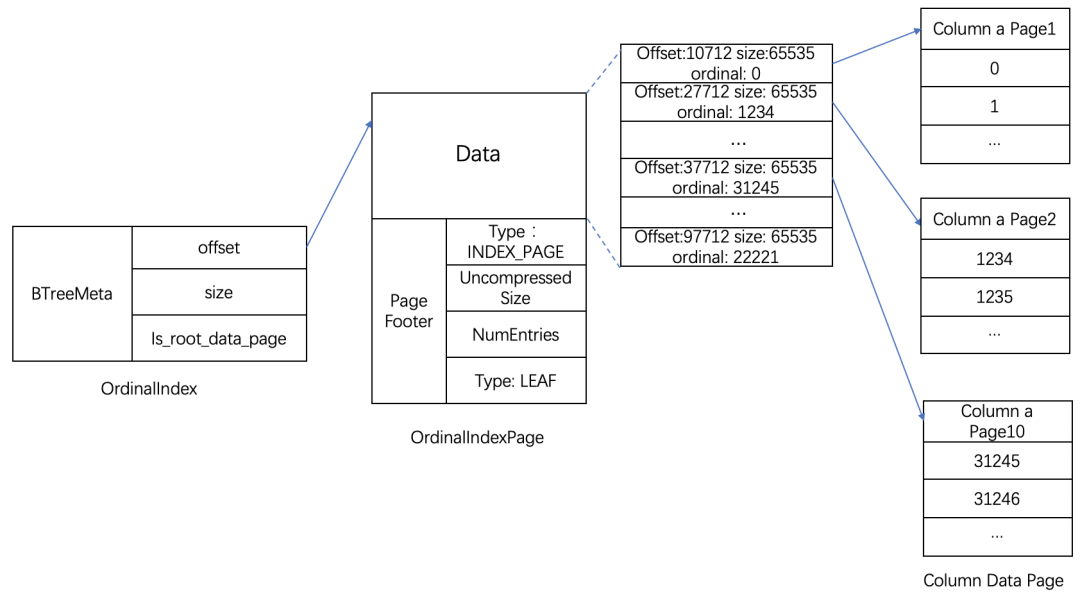
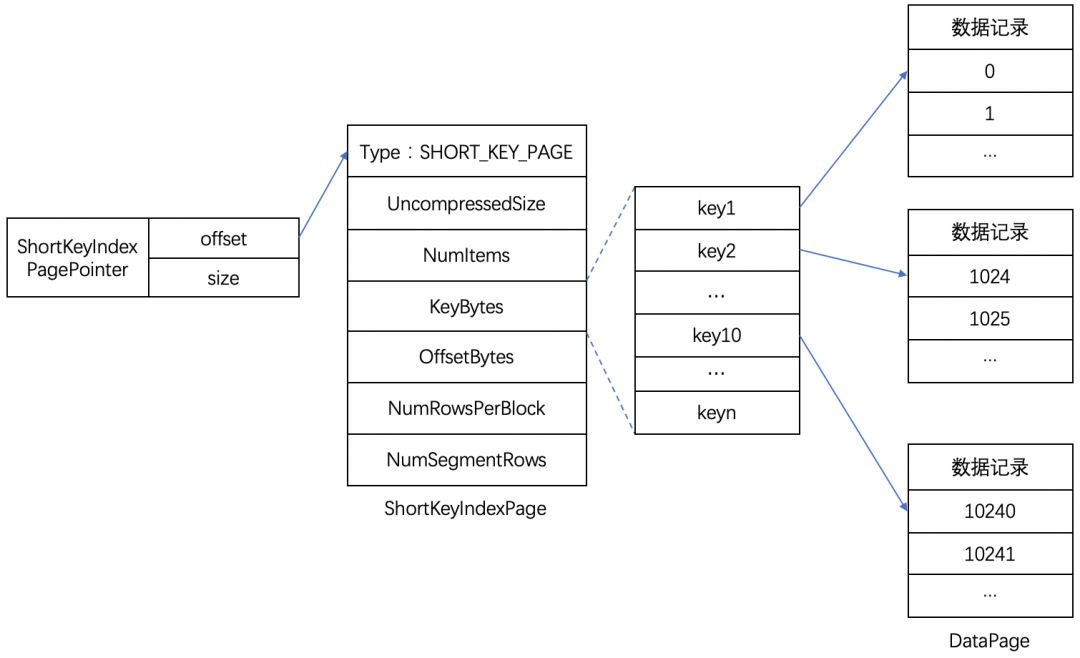
- Short Key Index(前缀稀疏索引)
- 索引的键选取策略是从排序列中选取,当排序列长度小于等于 36K,则直接选择所有排序列,反之,则只选择部分前缀(具体可看
Catalog#calcShortKeyColumnCount,大致意思就是选取前 36K 的字段),策略是在创建表时计算处理,创建完后,可以查询 Tablet 元信息查看选取的列。
- 在写入时,默认是每隔 1024 行采集一次,作为 Short Key 索引的一行;在查找时,二分得出 Short Key 索引的元素上下界的下标,下标乘以 1024 得出上下界的范围。
(比如:“查询维度列 X = ‘0a’” => “是 ShortKeys[0 .. 1] 之间” => “数据在 [0, 1023] 行”) - PS. 下图的 KeyBytes 是记录实际的索引键,而 OffsetBytes 记录的是对应的索引键在 Segment 文件的起始偏移量,用于启动时从磁盘中还原索引键列表。
- 索引的键选取策略是从排序列中选取,当排序列长度小于等于 36K,则直接选择所有排序列,反之,则只选择部分前缀(具体可看
- ZoneMap Index(数据区间索引,记录区间中的最值、空值)
在聚合模型下,即非 DUPLICATE 明细表模型,默认只对维度列使用 ZoneMap 索引,而只有在 DUPLICATE 明细模型时,默认自动对指标列添加 ZoneMap 索引。在实现上,ZoneMap 索引将分为两种,- SegmentZoneMap,描述整个 Segment 文件的索引信息。
- PageZoneMaps,每个 PageZoneMap 描述其对应的数据页 ID 的区间索引信息,同时,由于 Ordinal 索引中记录了页 ID 与页的起始行号与末尾行号的相互映射关系,因此,用户的查询条件最终会转化为行号范围的查询条件。
(比如:“查询指标列 A > 10” => “数据在页 0 和 2 上” => “数据在 [0, 31] 和 [64, 95] 行”)

- Bloom Filter(布隆过滤器)
- 看图就知道,与 ZoneMap 索引中的 PageZoneMaps 的结构一致。
(比如:“查询维度列 Y = ‘CN’“ => “数据只在页 0 上” => “数据在 [0, 31] 行”)
- 看图就知道,与 ZoneMap 索引中的 PageZoneMaps 的结构一致。
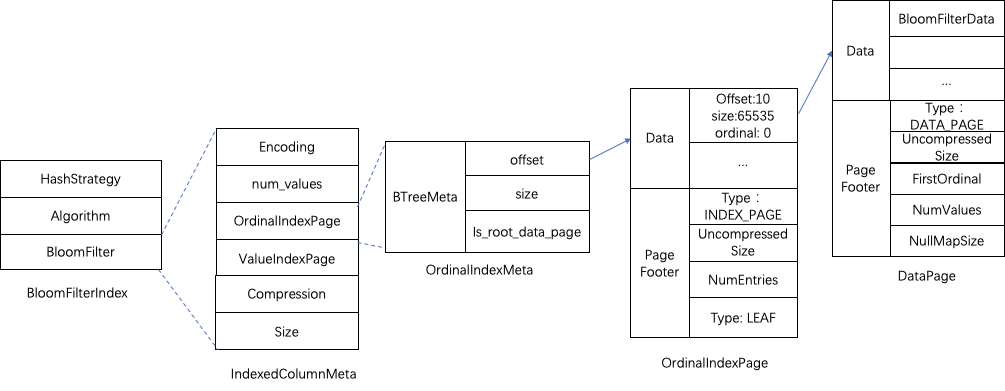
- Bitmap Index(位图索引)
- 从最末尾的图可以看出,分为 DictColumn 与 BitMapColumn 两组索引,而且,可见得,两者延展出来的存储结构是非常类似的,更重要的是,分别独立看,会发现与上文的 Bloom Filter 是一样的。
- 在写入时,构造位图索引列的数据与 Roaring BitMap(位图中记录数据的行号)的映射关系,映射的键列表(下图左侧)对应存储为 DictColumn,值列表(下图右侧)对应存储为 BitMapColumn,
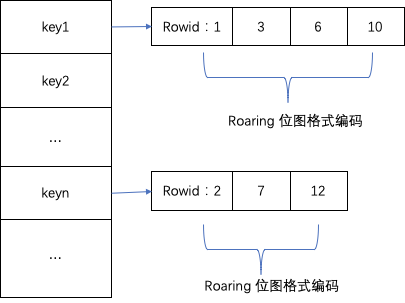
- 在查询时,当前版本,每次查询都会把所有位图索引的内容加载到内存,然后还原映射关系,即可从查询条件中得知其所在的具体行号。
(比如:“查询维度列 Z = ’XP‘” => “字典对应 1 号位图,内容 1000” => “数据在第 0 行”) - PS. 位图索引加载的次序是优于 Bloom Filter,这意味着,即便可以通过 Bloom Filter 快速判断数据不存在于某数据页时,仍需先花时间在加载位图索引上,但实际性能可能需要再深入分析。
Compaction 设计
Base Compaction,
Cumulative Compaction,
数据副本管理设计
读写策略
重分布
一致性检测
计算层设计
查询计划
Analyze SQL
构建 Plan Fragment
聚合模型一致性处理
向量化工程
enable_vectorized_engine性能分析与调试
DEBUG 日志
把 BE 或 FE 注释的配置设置为启用即可。
sys_log_verbose_modules = *
log_buffer_level = -1SQL Profile
set global enable_profile = true;
CPU & Heap Profile
Compaction Metrics
Core Dump & PStack
TPC-DS 性能测试
Dialect netezza,需要修改日期加减与 || 语法(也可设置 Doirs SQL Mode)。去掉不支持的 OR 子查询。
参考资料
- https://research.google/pubs/pub42851
- https://space.bilibili.com/362350065
- https://my.oschina.net/u/4574386/blog/4332071
- https://my.oschina.net/u/4574386/blog/4425351
- https://my.oschina.net/u/4574386/blog/4531386
- https://zhuanlan.zhihu.com/p/454141438
- https://arxiv.org/pdf/1603.06549.pdf
- https://arxiv.org/pdf/1709.07821v2.pdf
- http://algo.inria.fr/flajolet/Publications/FlFuGaMe07.pdf
- https://github.com/doris-vectorized/doris-vectorized
- https://en.wikipedia.org/wiki/Z-order_curve
- https://tildesites.bowdoin.edu/~ltoma/teaching/cs3225-GIS/fall15/Lectures/gis_zorder.pdf
- https://tildesites.bowdoin.edu/~ltoma/teaching/cs3225-GIS/fall16/Lectures/gis_zorder.pdf
- https://pythonawesome.com/numpy-implementation-of-hilbert-curves-in-arbitrary-dimensions/
- https://zhuanlan.zhihu.com/p/354334895
- https://github.com/WojciechMula/sse-popcount
- https://changkun.de/modern-cpp/zh-cn/00-preface/index.html
- https://github.com/apache/incubator-doris/issues/7196(MemTracker 优化,没细看)
- https://mp.weixin.qq.com/s?__biz=Mzg5MDEyODc1OA==&mid=2247484083&idx=1&sn=268f0db0614ff0288f108518ffecfa52&chksm=cfe012aaf8979bbc478439bacc885e9ef9b6a49a69c637144c6ec7dc35501aed1e7d26932153&scene=21#wechat_redirect
max_send_batch_parallelism_per_job
CONF_mInt64(write_buffer_size, “209715200”);
_tuple_buf = _table_mem_pool->allocate(_schema_size);
Create Table -> _create_tablet_worker_thread_callback -> StorageEngine#create_tablet -> TableManager#create_tablet
TypeEncodingTraits 类型编码与数据页的创建
FileBlockManager 写 Slice 到系统的桥梁,注释说可以合并 IO 优化
Roaring BitMap
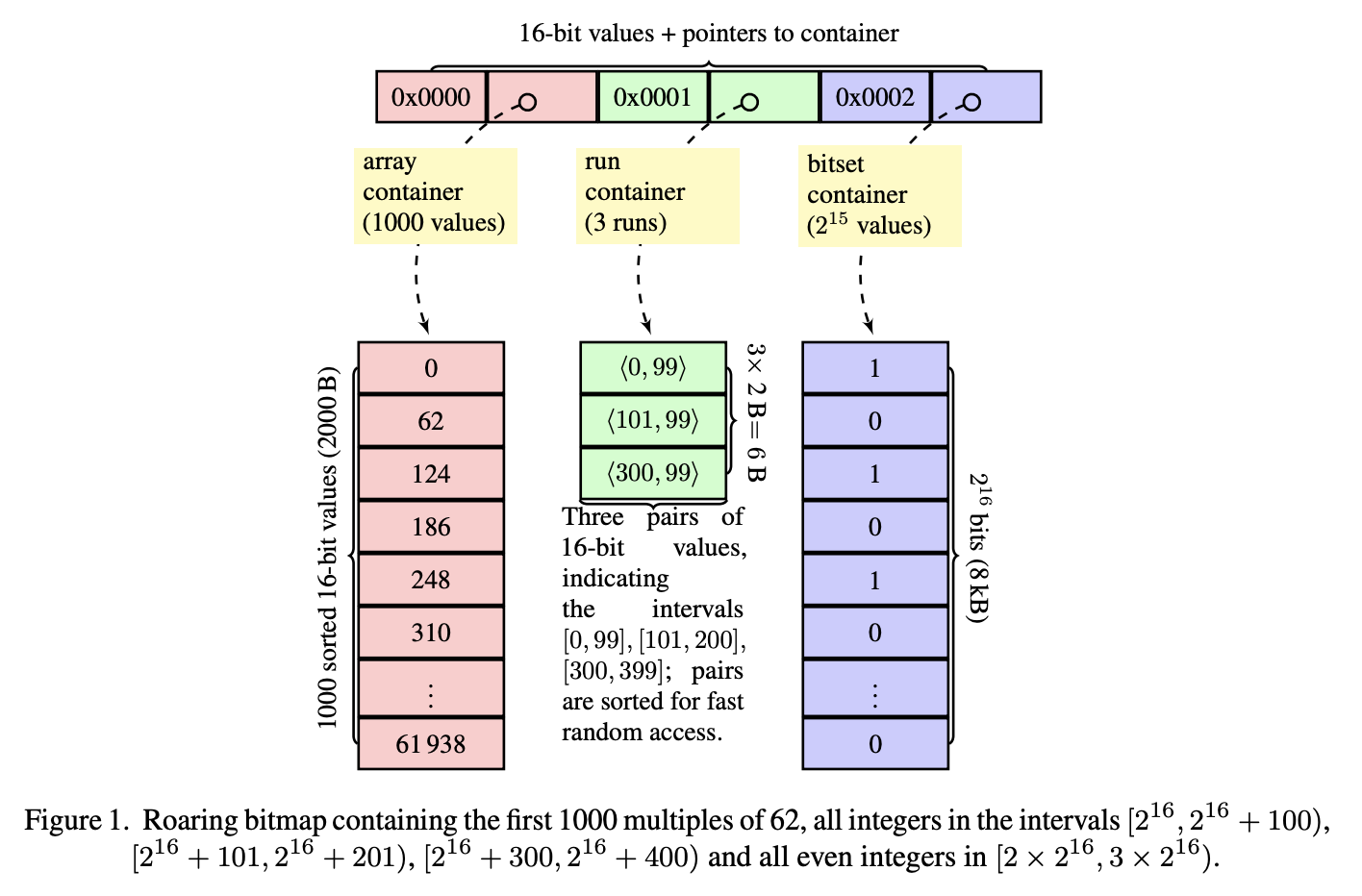
Roaring BitMap 论文分为两个部分:第一部分,如上图所示,是对位图存储效率的优化;第二部分,作者则花了大篇幅描述向量化算法实现,也是最值得我们讨论学习的地方。
向量化实现
- Population Count 填充计数运算 —— 求位串中 1 的出现次数
- 数组交集运算
- 数组并集运算
- 数组差集运算
Z-Order Curve

https://github.com/apache/incubator-doris/pull/7149
Rowset 相当于 LSM 树的磁盘子树,由 CollectIterator 对象负责归并读取并按需执行聚合函数。
有一个比较讨巧的设计,在现时的底层数据格式 Segment V2 下,数据段的写磁盘是不支持追加的,即内存必须全量记录数据(默认是 OLAP_MAX_COLUMN_SEGMENT_FILE_SIZE=256M),然后刷写出一份段文件,才释放这部分内存。
在大数据量时,段文件非常多,即便 Compaction 后也是如此,但是是正常的,因为,
- 普通情况下,从内存表中刷写到磁盘的数据段文件是可能存在区间重叠,也就是单文件内部有序,但文件之间无序,因此最终需要 Compaction 合成大文件以减少随机 IO。
- 而 Doris 的 Compaction 效果相当于把大文件再切分成小文件,此时文件全局有序,不再需要依赖归并排序来实现数据读取。
切分后的形态相当于分行了,好处是顺序扫描快、可实现分布式 Compaction,但小坏处是,
- 位图索引性能不可控。当查询不是排序键而是位图索引键时,就需要读取所有数据段文件的位图索引内容,并且,在任意查询时,位图索引目前是必须加载的,另外,根据百度云的文档显示,位图索引的合适基数固定值上限 10 万;
- 大量数据导入性能不可控。在刚导入大量数据的时候,查询性能由于未完成 Compaction 而产生陡峭的性能下降,但这可以通过按照分桶规则排序预处理(其实通过判断 ZoneMap 索引就可以了,但目前版本不支持,而相对的, HBase 的 Bulkload 导入对性能几乎无影响,但这主要是导入的问题,与文件格式关系比较少,只是顺带着说明一下现象)。
高基维上做索引,务必使用物化视图(可参考官方文档最佳实践 3),或者构建二级索引。