Parser Lexer yylval yyval ruleTable & tokenMap & windowFuncTokenMap Yacc %union 制定 Lexer 的 yylval https://github.com/mysql/mysql-server/blob/8.0/sql/sql_yacc.yy https://github.com/pingcap/tidb…
现代 C++ CMake add_library 可以导入导出链接库 ldd -r objdump -x / -T addr2line 值类别 参考维基百科的描述, 简而言之,左值是具有标识(变量名),默认只有拷贝语义,但可通过 std::move() 把左值修饰成临终值,具有可移动语义;右值不具有标识,是临时变量,像函数返回值(非引用类型),默认就具有可移动语义。 移动语义 同样的,根据维基百科…
无论是 MMv2 还是 MMv1,都建议把 MM 部署在 Sink 端,即,跨区消费 Source 端,本地写入 Sink 端,其主要原因是生产者对写入延时敏感(延时高了,数据将一直堆积在生产者内存中)。 Kafka Connect 数据互联模块是 MMv2 实现的基石,其提供外部系统写入 Kafka,以及从 Kafka 写出到外部系统的标准实现框架,并集合了 REST API 的动态配置中心、基…
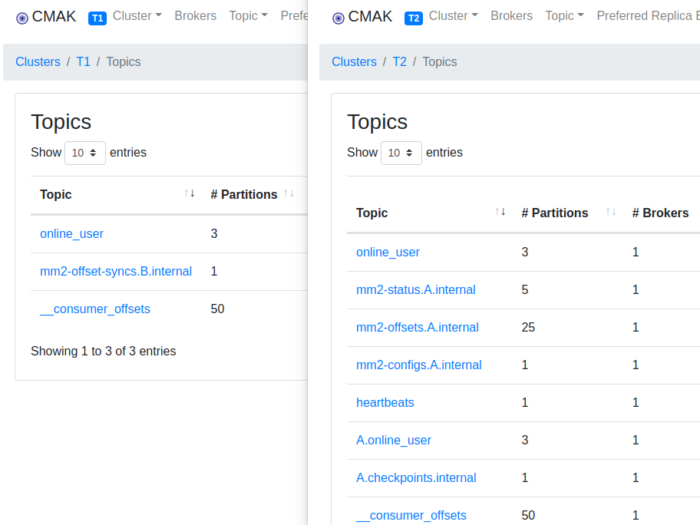
目前可能并不那么好用,但无碍它是一个设计精妙的 OLAP 系统。 基本背景 名词 解释 FE Frontend 角色,提供 SQL 解析与调度 BE Backend 角色,提供计算与存储 Broker 通过 Broker 隐藏访问远程文件系统(主要是 HDFS、S3)的具体实现细节 Tablet 一张表的分片,分片数量由分区与分桶数的乘积决定 Rowset 一次新的导入可理解为记录新版本的数据,R…
Google Mesa 是指标分析型数据仓库,主要服务于 Google AD 业务。本文抽离自 Apache Doris 的研究笔记,因此仅记录了论文中核心设计部分,省略了前置背景说明以及没有太关注的地方,原始全文是Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing。 存储结构 版本管理 定义 $deltas$ 为数据存储…
本篇主要讨论幂等与事务特性。 生产者的幂等与顺序特性 生产者通过配置 enable.idempotence=true 开启幂等特性时,会同时自动配置 acks=all 与 retries=INT_MAX_VALUE 以辅助幂等特性的工作。 实现原理 生产者端 在生产者端,持有 TransactionManager 事务管理器,其记录了 <TopicPartition, ProducerIdA…
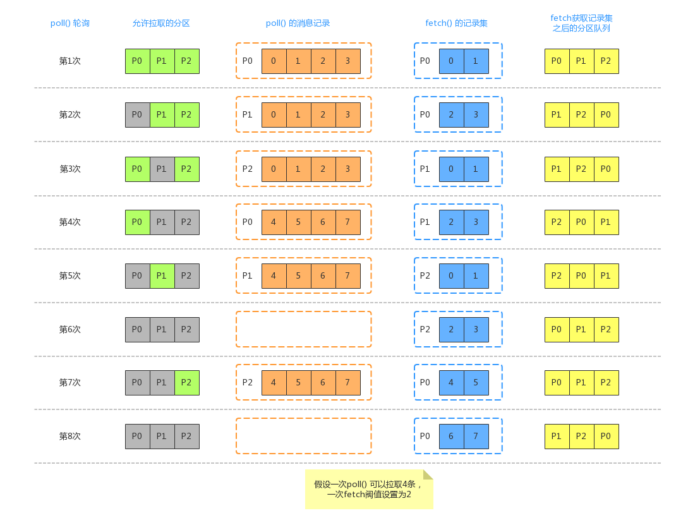
本篇主要讨论网络层基础架构、生产消费链路。 网络层 Broker 端 Reactor 模型 Broker 端的网络层设计基于 Reactor 模型。 在实际实现就是,EndPoint 对象提供监听的地址信息给 SocketServer 服务端对象,然后服务端启动一条 Acceptor 线程,专门用于 accept(2),并由 Acceptor 派生出 num.network.threads=3 条…
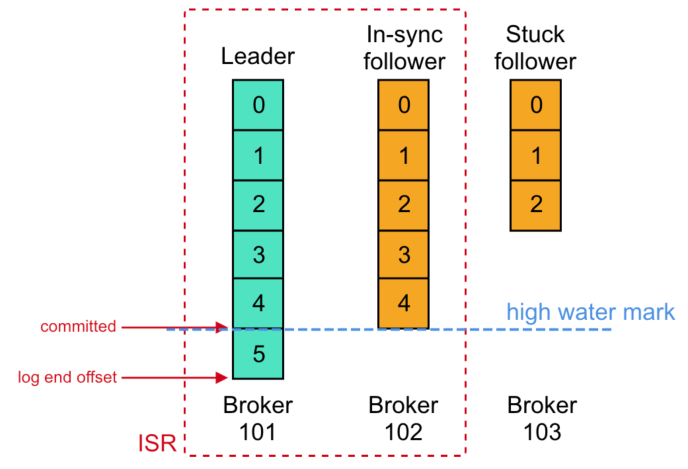
本篇主要围绕一致性副本复制协议、消息格式演进、消息落地上天以及其他细节的设计展开。 术语定义 名词 解释 Broker 又称 Kafka Server,是最基础的角色 Controller 一个 Broker 中活跃着 ZK 元数据管理服务的角色 Consumer GroupCoordinator 一个 Broker 中活跃着消费组元数据管理服务的角色 Consumer Group Leader/…
背景 启发自一位富裕女同事推荐的 CMU:15-445 与 15-721 数据库课程,但大部分都已经学过了,于是改头换面,顺便记录一下 Google 基于 BigTable 实现的 Percolator 事务算法。 设计初衷: 存储层框架 LSM 树 在写入时,LSM 树假设了磁盘文件数据的写入是有序的,如果输入数据无序,则会使用内存的有序数据结构,如跳表、红黑树(本设计采用红黑树),在一定量后溢…
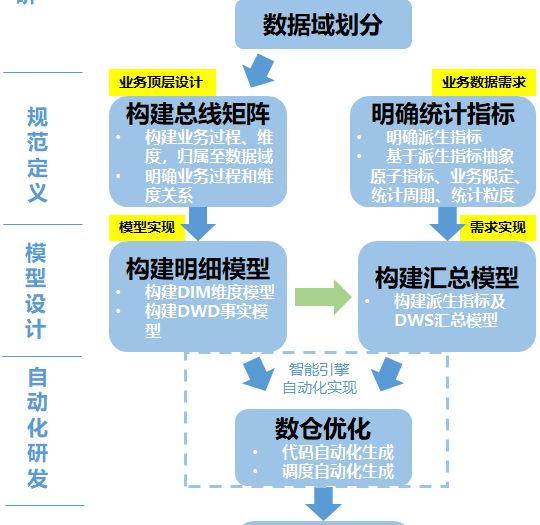
维度建模模型本质是对关系模型的修补,提出缓慢变化维度的处理方案,使其更适用于记录历史数据,同时提出一致性理论,使得新的业务也可以从数仓总线中复用原有的数据。 数据仓库的建模第一步与关系建模过程一样,从业务过程开始分析,关系模型关注业务过程所需的字段,而服务于分析系统的维度建模,在此基础上还需要关心分析需求的指标(推动埋点的设计);然后构建总线矩阵梳理出原子粒度的维度表与事实表,生成 DWD 层明细…