Cluster Replication 在 HBase 中不是一件容易的事情(但似乎 HBase 中就没有容易的事情 🙃)。 在阅读本文之前,首先需要了解 Sequence ID(以下简称 SeqId),在 HBase 中,一个 Region 的 SeqId 相当于代表该 Region 的“年龄”,新的 Region(比如新表刚创建,或者刚由父 Region Split 出来的两个子 Region…
Linux Futex 2002 年的《Fuss, Futexes and Furwocks: Fast Userlevel Locking in Linux》中提及,在实现用户态同步设计之前,用户态程序线程/进程需要对共享资源上锁,就得依赖内核态的信号量(在 System V 下提供 semop() 等函数、在 POSIX 下提供 semaphore 结构体;但由于 POSIX 格外提供线程同步…
两者虽然都依赖了 ProtoBuf,但都暗藏玄机。 总的来说,HDFS 的 RPC 分为两个大类:普通与流式 RPC,普通 RPC 全程传递的都是 ProtoBuf 编码对象,流式 RPC 则分为两段数据,一段 ProtoBuf 编码对象,一段一系列的 Packet 数据包。HBase 的 RPC 主要应用是批量传递 Cell[] 数据单元组,因此 HBase 使用未经 ProtoBuf 编码的 …
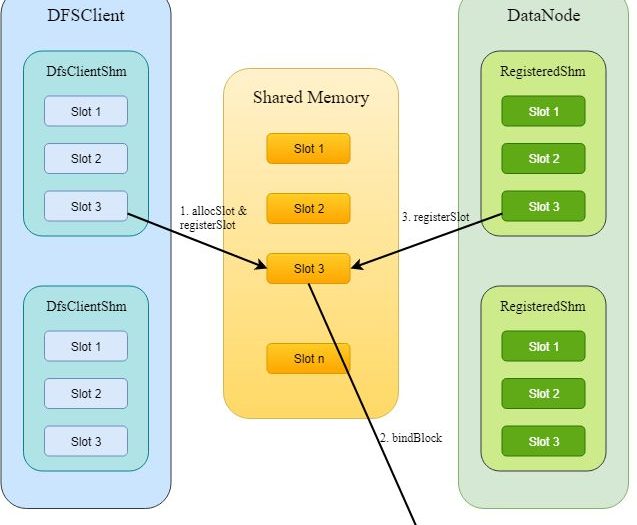
在 SSD 集群的 HBase 中, 硬盘 I/O 可能可以已经可以支撑很高的 QPS,但基于 HDFS 短路读的 HBase 在实际测试中可能并不如预期,这是因为短路读在共享内存的分配与回收上,其 QPS 也是非常高且消耗资源的 。所以 —— 短路读为什么依赖共享内存?直接传递文件描述符不可以吗? 在展开后文之前,需要说明,基于 UNIX Socket 在多进程间传递文件描述符,传递行为需要使用…
排序算法 快速排序 快速排序定义了 Pivot 中枢值,每次排序的目标是(下文均以升序为例),希望排序后的 Pivot 值位置的左区间都比 Pivot 值小,右区间都比 Pivot 值大,也就是希望排序后,Pivot 值位置是正确的,且左右区间都对 Pivot 值偏序。 因此在递归树中,每层能绕过扫描的数据是树上层确定位置的 Pivots 集合。当 Pivot 每次都选择在中位数上,每层分别确定出…
Raft 是一种用来管理日志复制一致性算法。 基本概念 算法限定每个 Server 只能为以下三种状态之一:Leader、Follower 和 Candidate。 算法通过强化 Leader 地位简化日志副本的管理,比如日志项只允许从 Leader 流向 Follower。 因此 Raft 把算法分解为三个子问题: 选主(Leader Election) 日志复制(Log Replication…