简述 Kafka Mirror Maker v2
无论是 MMv2 还是 MMv1,都建议把 MM 部署在 Sink 端,即,跨区消费 Source 端,本地写入 Sink 端,其主要原因是生产者对写入延时敏感(延时高了,数据将一直堆积在生产者内存中)。
Kafka Connect 数据互联模块是 MMv2 实现的基石,其提供外部系统写入 Kafka,以及从 Kafka 写出到外部系统的标准实现框架,并集合了 REST API 的动态配置中心、基于 Offsets 的同步进度管理、协作式重平衡协议等功能。
Connect 模块
Connect 模块的设计包含 4 种角色,2 种算子,4 种持久化的内部 Topics。
Roles
Connectors、Tasks、Worker 角色的关系,
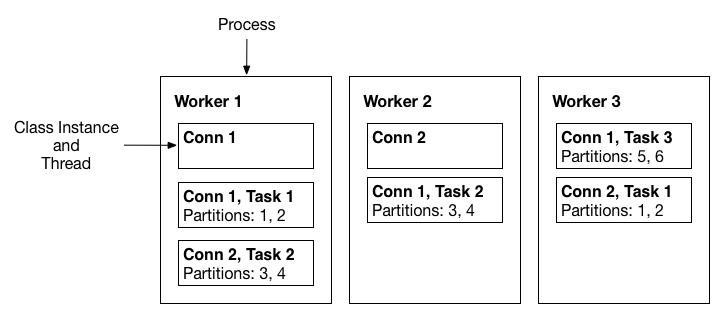
- Connector(以下简称为 Conn)分为两种,分别是,
- 处理外部数据源接入的 SourceConnector 类
- 处理写出到外部系统的 SinkConnector 类
- Conn 实例是对 Tasks 实例的管理模型,负责根据配置生成 Tasks;也通常有一个常驻线程,观察外部系统的变化情况,更新运行时配置,实现动态更新运行中的 Tasks。
- 一个进程对应一个 Worker,Worker 作为容器,管理着 Conns 与 Tasks 的生命周期。
Connector、Task 接口运作流程,Conn 主要依据 Connector#taskClass 指代的 Task 类、并行度参数 tasks.max,创建出 Tasks 实例,当 Task 属于 SourceTask 时,执行 poll() 拉取远端数据,写入到本地 Kafka 集群后回调 commitRecord() 的流程,相反,属于 SinkTask 时,执行 put() 往外部系统灌数据的流程。
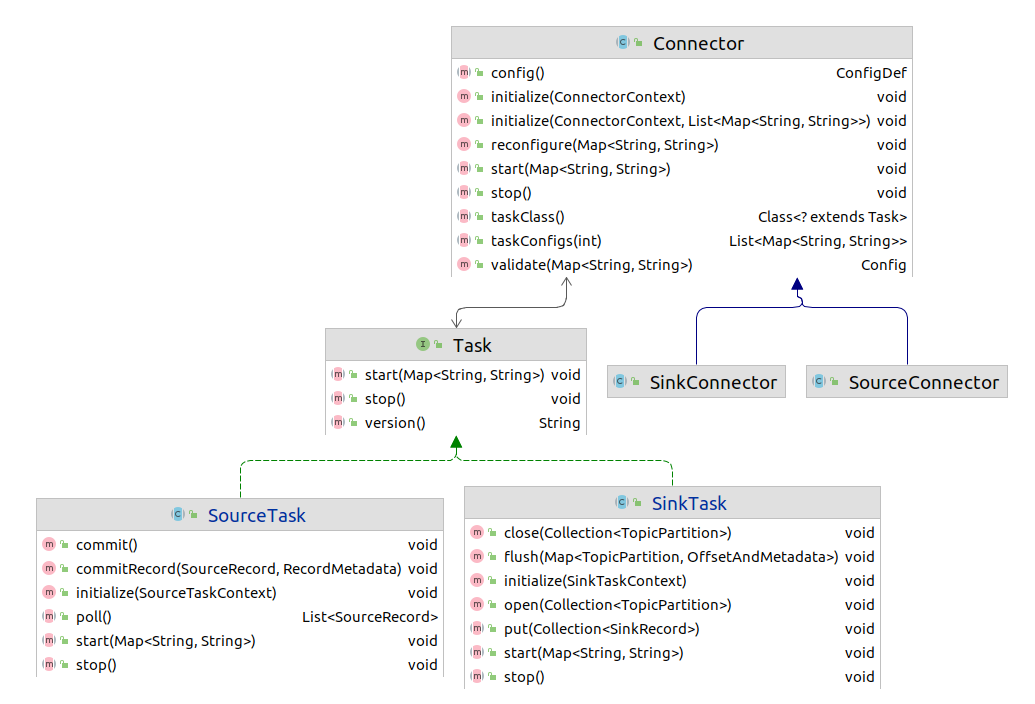
Herder 角色是对分布式节点级的管理,与 Worker 是一对一关系,提供对 Conns、Tasks 实例的管理接口,还有,当节点新增和失联时对任务进行重平衡处理(基于消费者模型实现)。
Operators
Converters 格式转换算子,用于格式转换,如 JSON 转 Avro,更多参考 Confluent 支持文档。
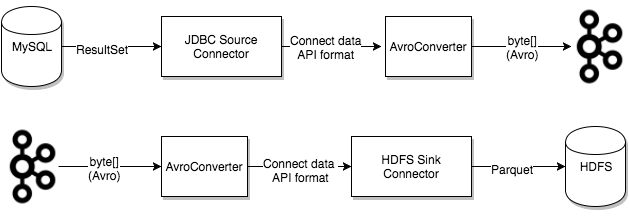
Transforms 数据处理算子,用于数据处理,如 Flatten 算子可以平铺展开嵌套的 Map。
Internal Topics
Dead Letter Queue 死信队列,仅用于上述两种算子执行过程中异常数据的处理。默认是遇到异常数据终止 Task,不会写到死信队列里。仅当配置了 errors.tolerance=all 及 errors.deadletterqueue.topic.name 时,异常数据才写入到死信队列。
connect-configs 配置信息事实表,由 KafkaConfigBackingStore 对象驱动读写,初始化于 Herder 构造函数,与此同时,对象内部的 KafkaConfigBackingStore$ConsumeCallback 消费者回调开始执行,一方面是形成 ClusterConfigState 配置快照表,另一方面是感知配置变更,触发重平衡以实现任务的重分配(相比较于普通的消费者重平衡,此处的 Connect 框架额外提供 scheduled.rebalance.max.delay.ms=5min 延迟重分配功能)。
注意,MMv2 自动同步新增或删除分区、Topic、消费组的功能,其实就是 Conns 启动定期检测元数据的线程,把配置变更信息写入到此事实表,KafkaConfigBackingStore\$ConsumeCallback 消费后触发重平衡流程,由 Workers 组 Leader 分配 Conns 和 Tasks,最终把结果写到每个进程的 Herder\$assignment 变量,然后执行 Conns 和 Tasks 重启操作。
connect-status 状态事实表,主要提供 Conns 与 Tasks 的状态写入、查询,没有衍生出状态机。
connect-offsets 外部数据源进度事实表,只提供给 SourceConnector 中使用。在使用 SinkConnector 时将不涉及该 Topic(因为 SinkTask 作为消费者消费 Kafka Topic,进度由 __consumer_offset 记录)。以 MMv2 为例,MMv2 启动时将回放该 Topic 作为起始同步进度。
Mirror Maker v2 实现
以下将以 A 为源集群,B 为写入集群 为例。只不过配置完成后(启用 A->B 同步流,关闭 B->A 同步流及心跳记录 Topic),有一个令人困惑的地方(尚不明确意图) —— 大部分辅助的内部 Topics 都默认创建在 B 集群,只有 mm2-offset-syncs.B.internal 孤零零的位于 A 集群。
另外的,由于大部分琐碎且麻烦的事情,Connect 框架都解决了,剩下的实现就比较简单了,
- 重命名 Connect 框架的内部 Topics,附带上数据源别名 A,以避免冲突。
- Topic:
connect-configs => mm2-configs.A.internal - Topic:
connect-status => mm2-status.A.internal - Topic:
connect-offsets => mm2-offsets.A.internal
- Topic:
- Mirror Source / 数据同步任务
- Connector,定期检测 ACL 配置、Topic 配置、Topic 分区数。
当检测到变更时,写入新配置到mm2-configs.A.internal的 Topic,由于 Connect 框架的 KafkaConfigBackingStore 一直在后台消费,所有 Workers 此时将观测到配置更新,执行重平衡流程,最终根据 Worker Leader 的分配结果,重启相关 Conns 及 Tasks。
- Task,实现数据同步。
MirrorSourceTask#poll 根据重平衡的分配结果消费数据源,MirrorSourceTask#commitRecord 提交二元组 <Consumer Offset, Producer Offset> 到 A 集群(即,困惑的地方)的mm2-offset-syncs.B.internal的 Topic。
理论上,MMv2 默认公设的,△ = Consumer Offset – Producer Offset 不变,这使得已知任意一种 Offset 可以推算出另一种 Offset。算式将使用在快照消费组 Offsets 时。
- Connector,定期检测 ACL 配置、Topic 配置、Topic 分区数。
- Mirror Checkpoint / 消费组 Offsets 快照(非实时)同步任务
- Connector,定期检测消费组列表。
与 MirrorSourceConnector 一样,配置更新写mm2-configs.A.internal,触发重平衡。 - Task,同步消费组 Offsets。
方法是拉取 A 集群的消费组 Offsets,然后通过 TopicPartition 与 Offset,根据 △ 不变,计算出下游 Offset,也就是 Producer Offset,写入到 A.checkpoints.internal。
- Connector,定期检测消费组列表。
- Mirror Heartbeat / 消费该 Topic 可获取最近一次同步时间
- Connector,无特别操作(除了默认的产生 Task 行为之外)。
- Task,发送心跳信息到 A.heartbeats。
- RemoteClusterUtils / 消费组同步结果查看
原理是消费 B 集群的 A.checkpoints.internal 实现,使用方法可以参考下一章节。
至此,通过以上设计,实现 MMv2。
Kafka 主备集群切换设计
环境准备
使用此 docker-compose.xml 可快速建立测试环境。注意调整 tasks.max 并行度参数。
示例代码
// 仅第一次切换恢复时候执行,还原 my-group 消费进度
Map<TopicPartition, OffsetAndMetadata> offsets =
RemoteClusterUtils.translateOffsets(properties, "A",
"my-group", Duration.ofSeconds(3));
Map<String, String> properties = new HashMap<>();
properties.put("bootstrap.servers", "kafka2:9092");
properties.put("group.id", "my-group");
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArrayDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.ByteArrayDeserializer");
KafkaConsumer<byte[], byte[]> consumer =
new KafkaConsumer<byte[], byte[]>(properties);
consumer.assign(offsets.keySet());
offsets.forEach(consumer::seek);
consumer.commitSync();
consumer.close();存在的问题
- 至少一次语义(△ 不变只在 Session 级,MMv2 重启可能破坏)。
- 主备切换时,生产者、消费者 bootstrap.servers 需要手动修改与重启。
参考资料
- https://docs.confluent.io/home/connect/self-managed/userguide.html
- https://docs.confluent.io/platform/current/installation/configuration/connect/index.html
- https://github.com/apache/kafka/tree/trunk/connect/mirror#monitoring-an-mm2-process
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-382%3A+MirrorMaker+2.0
- https://www.confluent.io/blog/incremental-cooperative-rebalancing-in-kafka/
- https://ibm-cloud-architecture.github.io/refarch-eda/technology/kafka-mirrormaker/