一个自制简易数据库 KxDB
背景
启发自一位富裕女同事推荐的 CMU:15-445 与 15-721 数据库课程,但大部分都已经学过了,于是改头换面,顺便记录一下 Google 基于 BigTable 实现的 Percolator 事务算法。
设计初衷:
- 实现高性能的存储引擎,减少内存复制延迟,以及实现更深入的 I/O 性能优化,
- 实现查询引擎,希望基于 KV 实现出复杂的查询优化场景,
- 使用 Lustre 类似的并行文件系统,并发对文件块进行查询,
- 最终实现计算与存储分布式,这是个大坑。
存储层框架
LSM 树
在写入时,LSM 树假设了磁盘文件数据的写入是有序的,如果输入数据无序,则会使用内存的有序数据结构,如跳表、红黑树(本设计采用红黑树),在一定量后溢写到磁盘。溢写发生时,对有序数据建立类似 B+ 树的一维空间索引,由于此时输入数据有序,索引的建立也是顺顺利利,不像 B+ 树添加/删除数据时候还需要覆盖索引改动的数据块 ,还有考虑并发修改问题。
但有一个不好处理(不太优雅)的点,客户端 Scan Memstore 的红黑树时,是有状态的(也就是每次遍历一点点,然后再从上次遍历的数据再往后遍历),这需要遍历时候至少需要分阶段上锁或者无锁,而不能一直锁住直至所有遍历完成,但写入 Memstore 时,红黑树的结构可能一直在变更,所以查询上次进度需要重新从根开始计算,并且可能需要分阶段上锁,每遍历一个阶段的数据,上锁然后复制数据出来返回给客户端。
KV 分离是 LSM 树对大对象存储的优化,方法是 KV 的 Value 字段记录指针而非用户数据。
Buffer Pool / Block Cache
采用朴素的 LRU,但是由于在 C++ 上实现,需要手动释放内存,因此需要考虑标记 LRU Cache 的数据块是否可释放,evict 驱逐时候把未能释放的块放到待 GC 集合保留,当数据块再次被使用时,可直接拉回 LRU Cache 中,而如果数据块未被再次使用并触发了释放操作,数据块将释放并从待 GC 集合中删除。
这样可避免同一份数据,被各种操作复制多次使用。
Bloom Filter
在 256KB 块上对 131072(128K) 个 rowkeys 进行 BKDRHash + DEKHash + FNVHash + APHash + JSHash 哈希取样,测试结果准确率在 99.85% 左右。
但 Bloom Filter 目前只针对点查有效,范围查就凉了,未来可以考虑优化(配合线段树区间查询?但似乎作用不大);还有它的数学概率分析公式实在没搞懂,挖坑日后再研究。
WAL
暂未实现,日后待更。相比较传统数据库快照隔离 MVCC,在 HBase 中,MVCC 只是控制 WAL 落地前后的可见性,其依赖 Read Point 与 Write Point 实现,当数据从 WAL 刷写磁盘成功后,推进 Read Point 到刷写的 Write Point。
计算层框架
事务管理框架
单机的实现
单机的事务隔离通常由下面几种机制联合实现:
- ReadView(快照隔离的 MVCC 实现,用于 Read Committed 与 Repeatable Read 隔离级别)
- Index-Range Locking(也称为 Gap Lock,解决快照隔离的 Write Skew 写偏差问题)
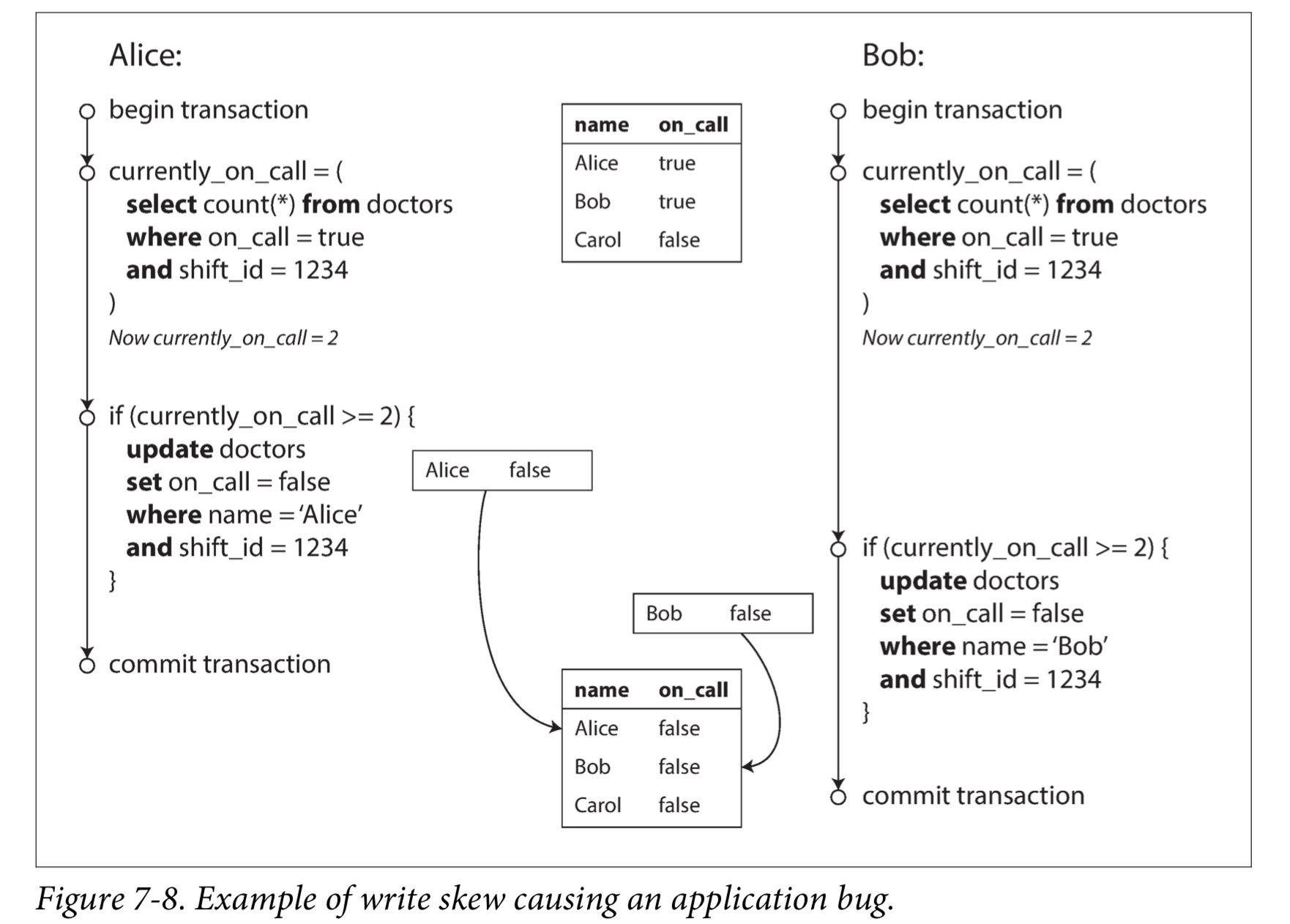
- S2PL(Strict Two Phase Locking Protocol,严格二阶段封锁协议)
仅用于实现 Serializable 隔离级别。在课本中,S2PL 也可实现其他隔离级别,
但由于并发性能太差,在现代数据库中非 Serializable 级别都使用快照隔离的 MVCC。
在配置 Serializable 级别的 MySQL ,会在 SELECT .. 中隐式添加 LOCK IN SHARE MODE。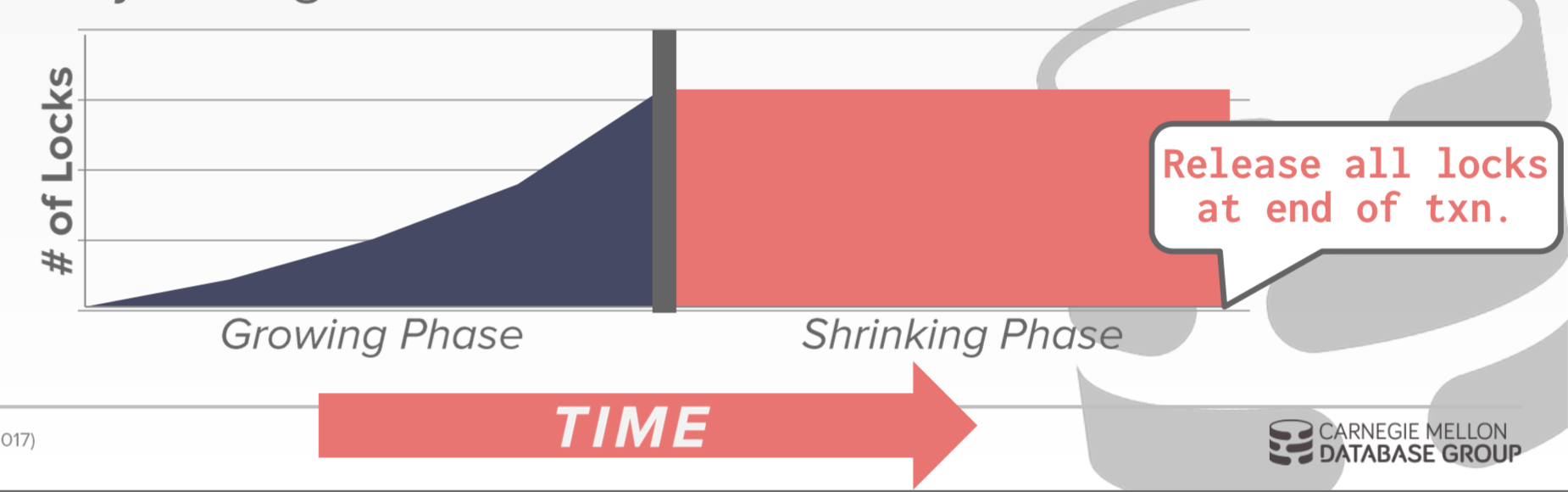
- MGL(Multiple Granularity Locking,多粒度锁,共享读锁、互斥写锁、更新锁)
用于辅助 Gap Lock 和 S2PL 的锁实现。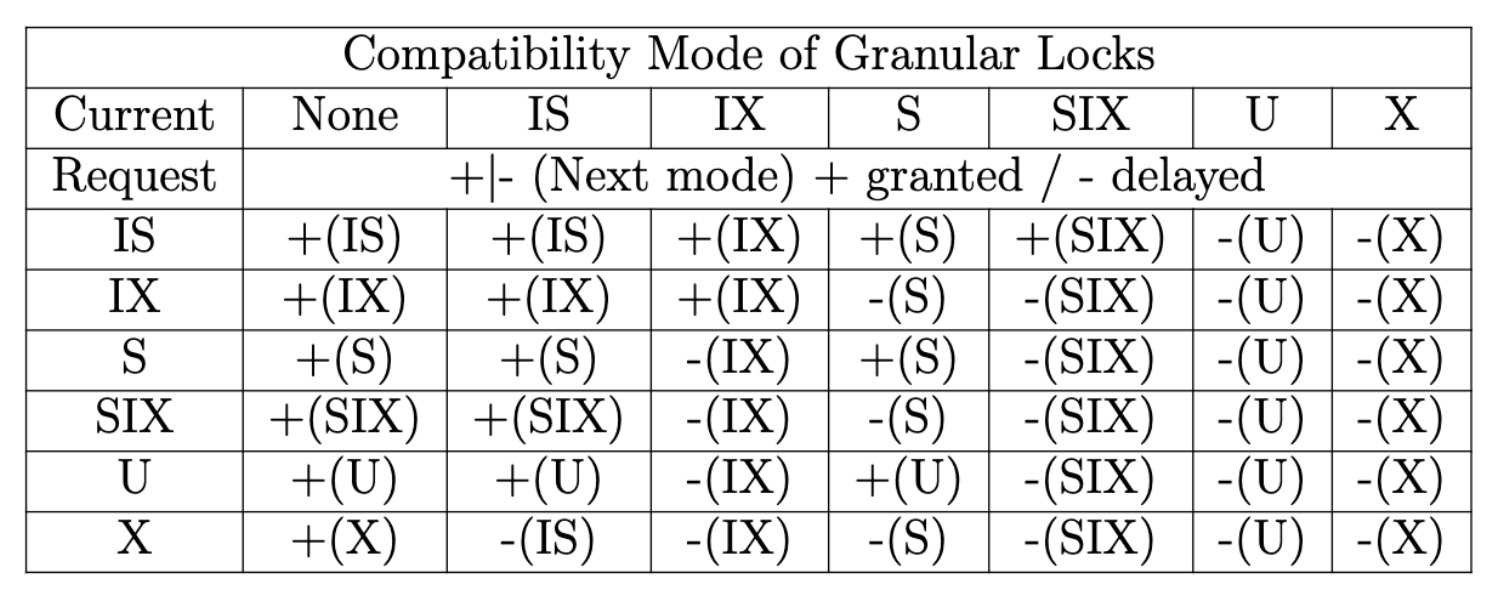
PostgreSQL 提供 SSI(Serializable Snapshot Isolation,可串行化的快照隔离),通过检测旧 MVCC 的读取、检测影响之前读取的写入,直接终止有影响的事务。
分布式实现
Percolator(TO + MVCC)
《Large-scale Incremental Processing Using Distributed Transactions and Notifications》
及其三种优化技术,分别是缓存提交写、管道和并行提交。TiDB 采用“缓存提交写”达到了 2 倍共识算法延迟,但这个方案的缺点是缓存 SQL 的节点会出现瓶颈,而且不再是交互事务。CockroachDB 采用了管道和并行提交技术,整体延迟缩短到了 1 倍共识算法延迟,可能是目前最极致的优化方法了。
实现代码

基础实现:https://github.com/akiasprin/KxDB
参考资料
- https://vonng.github.io/ddia/#/
- https://time.geekbang.org/column/intro/100057401
- https://www.youtube.com/c/CMUDatabaseGroup
- https://15445.courses.cs.cmu.edu/fall2021/assignments.html
- https://www.jianshu.com/nb/36265841
- https://wiki.postgresql.org/wiki/SSI
- https://pingcap.com/zh/blog/tidb-internal-1
- https://pingcap.com/zh/blog/tidb-internal-2
- https://pingcap.com/zh/blog/tidb-internal-3
- https://www.cnblogs.com/CodeBear/p/12710670.html
- https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36726.pdf
大佬!一句都听不懂,膜拜膜拜。
OI 大佬谦虚了~