深入 Kafka Core 的设计(核心设计篇)
本篇主要讨论网络层基础架构、生产消费链路。
网络层
Broker 端
Reactor 模型
Broker 端的网络层设计基于 Reactor 模型。

在实际实现就是,EndPoint 对象提供监听的地址信息给 SocketServer 服务端对象,然后服务端启动一条 Acceptor 线程,专门用于 accept(2),并由 Acceptor 派生出 num.network.threads=3 条 Processor 线程,Processor 线程专门用于与 IO 多路复用的 Selector 模型进行交互,当确保客户端发送的数据被完整的接收后,放置在 RequestChannel$requestQueue 队列中,由 num.io.threads=8 条处理 Kafka 内部业务的 KafkaRequestHandler 线程传递给 KafkaApis 单例对象处理业务逻辑。
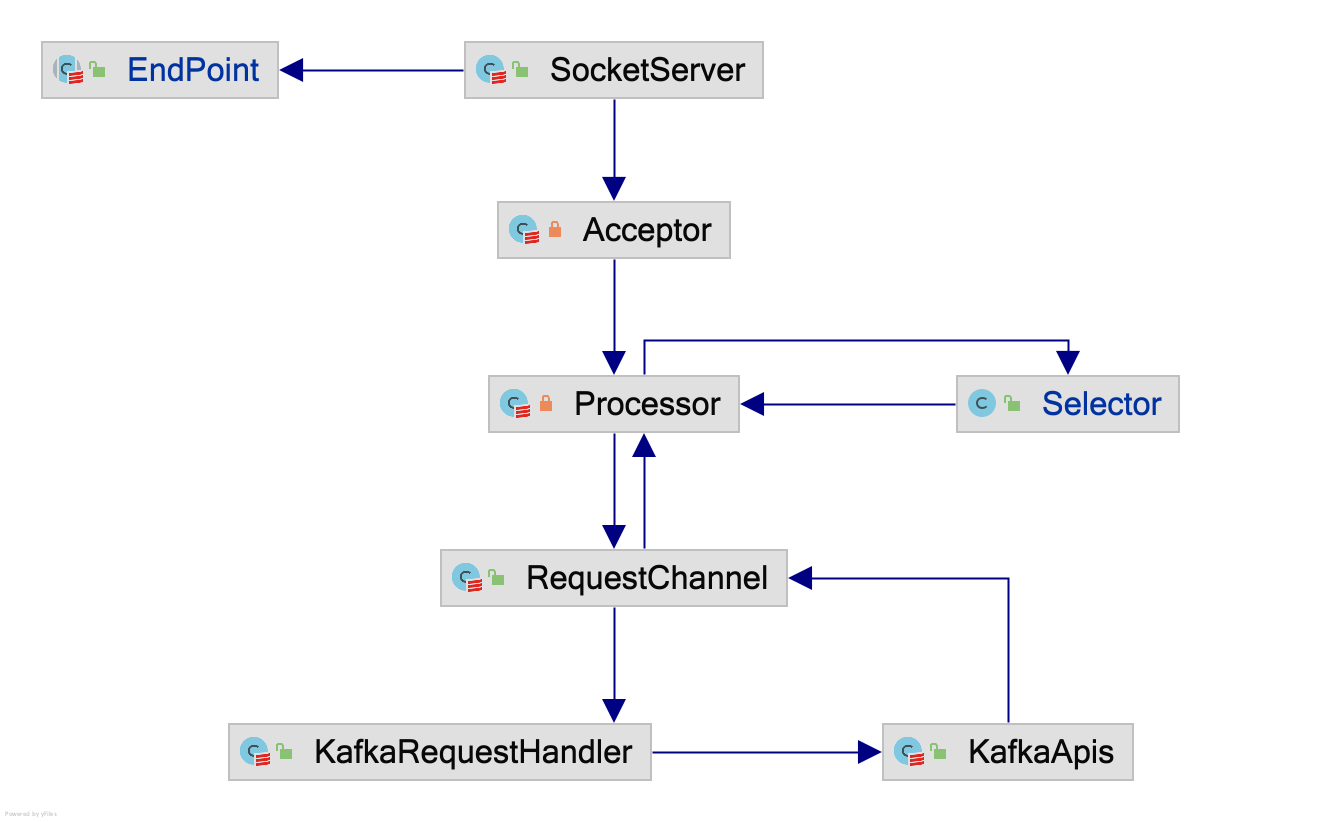
Kafka Selector 框架
Java API,把 OS 的 Socket 的文件描述符具体成 SocketChannel,然后 SocketChannel#register 方式注册并设置关注事件到 NIO Selector,但与 OS 的不同,它是会返回 SelectionKey 上下文对象(其包含 Channel 也就是文件描述符,以及附件 Attachment 对象),这就是 Java NIO 其中一个通用化设计,内部实现其实是记录了文件描述符与 SelectionKey 对象的 Map 映射关系,当就绪事件(Ready)的文件描述符拿出来时,可以顺便找到 SelectionKey 对象,还原就绪前的上文(简单来说,就是在未就绪前通过 SelectionKey#attach 附注上数据状态,然后就绪时候,通过 SelectionKey 即可获取未就绪时的数据状态)。
而基于 Java API 的 Kafka Selector API,实现透明 SSL 层、解决粘包问题(或者称作非阻塞 IO 下的 Eager 读写不完整问题)。因此 Processor 与 Selector 的数据交互,通过 KafkaChannel + NetworkReceive/NetworkSend + TransportLayer 类,隐藏了对数据包的网络 IO 处理,因而在 Processor 中看起来,所有的请求都是完整的符合格式的请求。

具体的实现是,
- 在
accpet(2)接受请求后,得到与客户端的 SocketChannel,即 Socket 的文件描述符,然后注册到 Selector 模型得到 SelectionKey 对象,并通过 SelectionKey#attach 附注上 KafkaChannel 上下文对象 - 在读就绪时,Selector 模型返回可读的 SelectionKey 对象,通过其附注的 KafkaChannel 下的 NetworkReceive 对象从 SocketChannel 读取 4 字节的当前报文长度信息,然后持续读取报文的正文部分
- 在写就绪时,也一样,Selector 模型返回可写的 SelectionKey 对象,通过其附注的 KafkaChannel 下的 NetworkSend 对象往 SocketChannel 持续写入数据
Kafka Channel 上下文对象
KafkaChannel 与底层 TCP 链接(比如生产者往某一 Broker 所创建的 TCP 链接)是一对一关系。
虽然叫作 Channel,但更多作用是用于 IO 就绪时回调的上下文线索。
比如发送的实现,分两步,首先是往 Selector 注册可写就绪的关注点,其次给出可写就绪时候应该写出什么数据的线索,即下面的 send 变量。
public class KafkaChannel implements AutoCloseable {
private NetworkReceive receive;
private NetworkSend send;
public void setSend(NetworkSend send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
//...
}但更值得注意的是,上面抛出的 IllegalStateException,其说明了往 KafkaChannel 写的数据,必须等待前置的请求完成,这意味着指向同一个 TCP 链接的所有请求,都需要一个队列,以保证发送次序,所以在后面,无论是生产者还是消费者在发送请求时候,都能看到依赖队列依次发送。
Client 端
客户端的网络层主要围绕基于 Kafka Selector 模型的 NetworkClient 对象,其提供最基础的消息发送、拉取与元数据模型查询接口,基于此构造的分别有,直接服务于生产者的 Sender 对象与消费者的 Fetcher、ConsumerCoordinator 对象。

相比较生产者端,消费者端还格外实现了 ConsumerNetworkClient,这是因为,已知 Kafka Selector 模型的发送方式仅支持依次逐个发送,而 Fetcher 与 ConsumerCoordinator 可能同时对某一个 Broker 发起请求,那么则需要使用队列来协调请求发送的轮次,也因此 ConsumerNetworkClient 对象主要功能就是实现此发送队列。
public class ConsumerNetworkClient implements Closeable {
private static final class UnsentRequests {
// 节点对应的未发送请求队列
ConcurrentMap<Node, ConcurrentLinkedQueue<ClientRequest>> unsent;
public void put(Node node, ClientRequest request) {
synchronized (unsent) {
ConcurrentLinkedQueue<ClientRequest> requests =
unsent.computeIfAbsent(node, key -> new ConcurrentLinkedQueue<>());
requests.add(request);
}
}
}
}生产链路
- 单条的 ProducerRecord 消息累积成 ProducerBatch 批消息
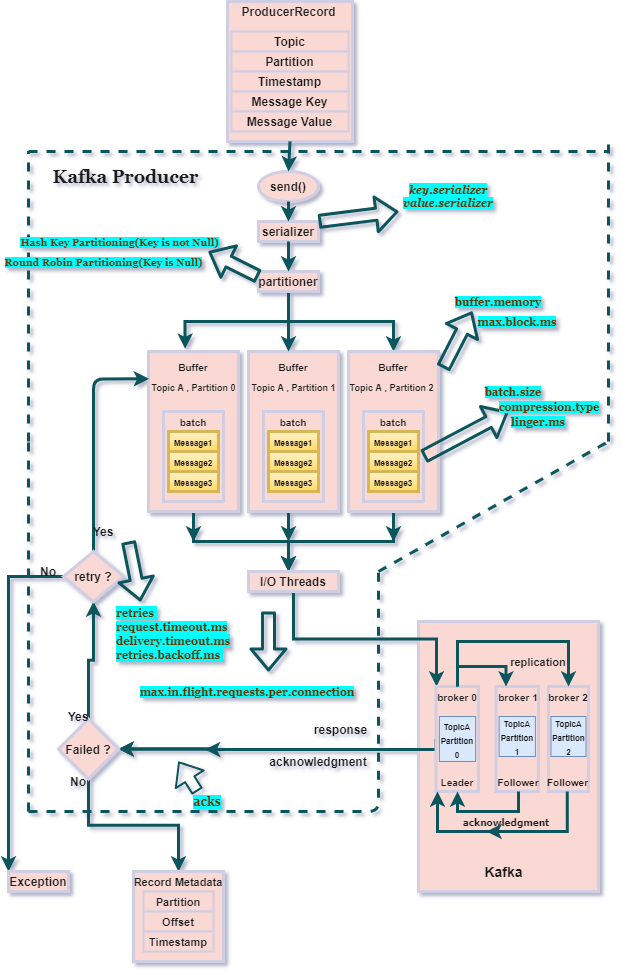
Producer 在发送数据前首先获取元数据(主要获取分区与主副本 Broker 的映射关系,先不展开),然后计算目标分区 ID,但这个可以用户指定,也可以通过 Partitioner 对 serializedKey 序列化后的键计算出分区 ID,最终,业务所生产的单条消息交由 RecordAccumulator 对象扔到其内部的Map<分区ID, Deque<ProducerBatch>>映射的双端队列中尾部的 ProducerBatch 批消息里暂存。
其中,可用于测算分区 ID 的 Partitioner 有:- DefaultPartitioner,Key 为空随机,否则根据 Key 的哈希值分区
- RoundRobinPartitioner,轮询机制分区
- UniformStickyPartitioner,为了减少累积导致的延迟,一个 Batch 之内的数据为一个分区
- 批消息发送
发送的核心是把Map<分区ID, Deque<ProducerBatch>>转换为Map<BrokerID, Deque<ProducerBatch>>,具体来说,首先判断是否满足batch.size批大小或者linger.ms最大暂存时间,然后关联分区 ID 与主副本 Broker ID 关系的元数据进行转换,构建请求,当满足目标节点小于max.in.flight.requests.per.connection=5最大在途的请求限制,且上轮的发送已完成,交由 IO Thead,即 Sender 对象,执行异步发送请求,最终在 IO Thread 回调 Callback#onCompletion。 - 主副本的落盘与 Acks 的同步机制
持有主副本的 Broker 接收到 ProduceRequest,交由 ReplicaManager#appendRecords 分别进行 appendToLocalLog 日志落地(落地过程可参考上篇)与注册 DelayedProduce 延期操作(最大等待时间等于请求超时,默认request.timeout.ms=30s),等待从副本的同步完成(仅在acks=all时;而acks=1与acks=0的区别在于生产者端是否需要等待主副本落地成功的响应)。 - 从副本的同步
要说副本同步,就得说回 Broker 启动初始化流程与水位线更新流程:- 初始化流程
在 ZK 模式下,Broker 启动过程会往 ZK 上注册节点,此时 Controller 的 ZooKeeperClientWatcher#process 监听并发现到节点变更,执行发起 LeaderAndIsrRequest 上线关联副本集,收到上线请求后的 Broker 中触发 makeFollowers 流程,把相关分区副本设置为 Follower 并初始化 Fetcher 拉取线程池(默认线程数num.replica.fetchers=1),每个拉取线程所管理拉取的分区相互独立。每个拉取线程首先收集本地分区日志的起点 LSO 与终点 LEO,并以每分区拉取大小为replica.fetch.max.bytes=1M,本次累计总拉取大小replica.fetch.response.max.bytes=10M的配置发起 FetchRequest 拉取请求 。 - 水位线更新流程
主副本收到 FetchRequest 拉取请求后,读取日志(读取过程可参考上篇)并更新remoteReplicasMap集合中对应远程 Broker 的副本情况(LSO、LEO),然后根据remoteReplicasMap中 ISR 列表的最低的 LEO,更新分区的 HW,如果此时 HW 大于等于之前生产请求写入的 LEO,则该批消息的从副本的同步完成,生产者会收到 ProduceResponse 回应,另外,从副本也会收到 FetchRespons,得知现在主副本的最新情况(LSO、LEO)。
- 初始化流程
消费链路
以设计完备的高阶消费者为视角,其在消费链路主要包含,
- 订阅 Topic 集合
- 加入到以
group.id=xxx命名的消费组
消费者们发送包含group.id的 FindCoordinatorRequest 请求给任意 Broker 查询 Group Coordinator 地址(计算 Group Coordinator 地址可参考上篇),接着,发送 JoinGroupRequest 到 Group Coordinator 请求加入消费组,Group Coordinator 收到请求后,把这些消费者节点加入到成员列表里,并以第一位加入此消费组的消费者作为 Group Leader,通过 JoinGroupResponse 回应给所有消费者。 - 由消费组 Group Leader 分配各消费者所属的 <Topic, 分区> 二元组集合
当 Group Followers 的消费者在收到 JoinGroupResponse 后,接下来,会直接发送 SyncGroupRequest 请求给 Group Coordinator,而作为 Group Leader 的消费者,需要先调用 AbstractCoordinator#performAssignment 接口,分配各消费者所属的 <Topic, 分区> 二元组集合(代码中对应 TopicPartition 类,下面简称 TopicPartition),然后把结果通过 SyncGroupRequest 请求发送给 Group Coordinator,最终由 Group Coordinator 把分配结果通过 SyncGroupResponse 回应给所有消费者。 - 获取各 <Topic, 分区> 的起始消费的 Offsets
首先,提交的 Offsets 是下一条业务需要消费消息的偏移量,拉取的 Offsets 也是未被消费的偏移量,所以,当配置了enable.auto.commit,提交的 Offsets 是直接取自记录了未来需要拉取的 Offsets 的 TopicPartitionState 对象。
在获取 Offsets 行为中,消费者根据 OffsetFetchResponse 拉取结果分为两种情况,第一种是 Group Coordinator 返回了上次消费进度 Offsets,消费者通过 seek API 直接定义拉取的起点信息即可;第二种是没有上次进度,以消费者配置auto.offset.reset策略对 Group Coordinator 发送 ListOffsetRequest 请求,Group Coordinator 根据请求策略来决定 LSO 还是 LEO 作为拉取的起点。
另外,默认的auto.offset.reset=latest,这可能会使在添加新分区操作时,新分区的元数据未来得及更新,生产端已经对新分区进行数据写入,根据 latest 策略,消费端得到新分区的 LEO 值,导致消费端遗漏数据。 - 拉取订阅的数据(请参考下面的数据拉取实现)
- 提交 Offsets(请参考下面的 Offset 提交操作)
除了数据拉取之外,所有管理的行为其实都围绕着 __consumer_offsets 这个内部的 Compacted Topic,所以,接下来,我们首先整体关注 __consumer_offsets 是如何驱动消费组与消费者的管理。
__consumer_offsets
首先,__consumer_offsets 是记录了两种数据,分别是,
- 以 GroupTopicPartition 为主键, Offset 为值的记录。
- 以 Group Id 为主键,GroupMetadata 为值的记录,其中 GroupMetadata 对象不仅包含组成员信息,还包含所有消费者 TopicPartition 的消费进度,即 Offsets。
其次,__consumer_offsets 可以理解成消费端事务型事实表(记录组成员的流失与新增等事件),而 GroupMetadataManager$groupMetadataCache 内存对象则是对应的快照事实表,所有的查询都基于该快照表。
相关操作
- 初始化链路
初始化发生在当前 Group Coordinator 的__consumer_offsets分区副本被选为主副本,触发 GroupMetadataManager#loadGroupsAndOffsets 回放__consumer_offsets的 Records。 - 持久化链路
持久化交由 ReplicaManager#appendRecords,与生产链路中 Broker 端,逻辑一致。 - Offsets 提交
Group Coordinator 在收到 OffsetCommitRequest 请求后,除了上面的对 Offsets 持久化外,还会更新对应 TopicPartition 在 GroupMetadataManager$groupMetadataCache 的缓存。 - Offsets 拉取
对应 OffsetFetchRequest 或者 ListOffsetRequest,前者读缓存,后者取 LSO 或者 LEO。 - 消费组重平衡
消费组重平衡
流程
消费组成员变更主要发生在两个地方,
- 第一种,被动的,在 Group Coordinator 端的,基于心跳检测的,当两次心跳间隙超过
session.timeout.ms=10s,认为消费者已离线,剔除成员。 - 第二种,主动的,在消费者端的,当两次 poll() 间隙超过
max.poll.interval.ms=5min,认为消费过程阻塞,主动离开消费组。
无论是哪一种触发的发生成员变更,Group Coordinator 的处理是,
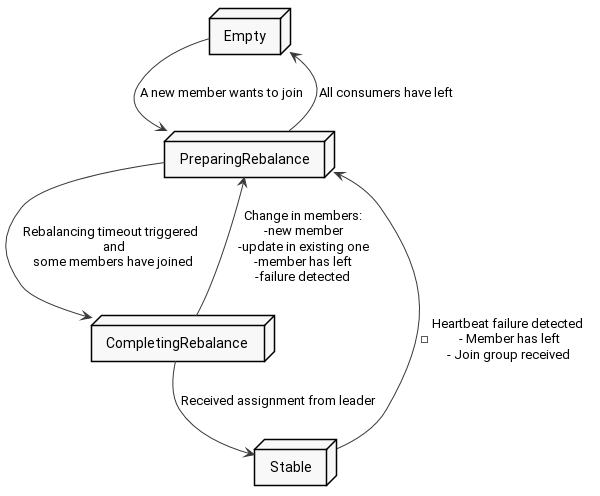
标记 Group State 由 Empty 或者 Stable 状态转移到 PreparingRebalance 状态,此时开始准备重组消费组成员,当前置状态在 Empty 时,会等候更多成员的加入,而前置状态在 Stable 时,可以直接认为 PreparingRebalance 状态已经完成(事实上,取决于版本,可能会有同步新分配的用于标识组成员 ID 的 memberId 过程,leaderId 是其中一个 memberId),然后递增消费组元数据的 generationId 代数,目的是避免处于卡顿状态的消费者在恢复时,感知不到消费组已经剔除它了,接着进入 CompletingRebalance 状态,等待 Group Leader 分区分配结果并由 Group Coordinator 同步给所有消费者,无论是否同步成功,最终进入 Stable 状态。
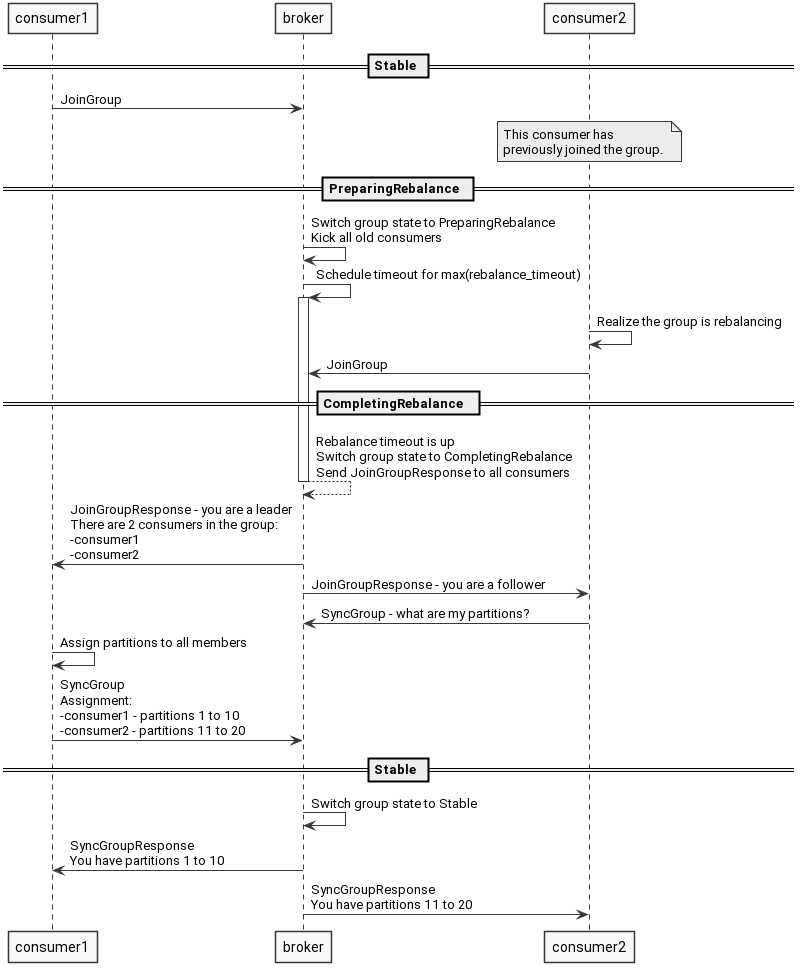
具体执行流程可参考时序图,其中 consumer2 在心跳中得到 Errors.REBALANCE_IN_PROGRESS 错误,会主动申请重新加入组,以同步最新的组信息与分配情况。
分配策略
Group Leader 在分配分区时,主要有三种基本分配策略,
注意,不同的分区分配策略只解决消费组内订阅了多个 Topics,且可能存在每个消费组成员订阅不同的 Topics,从而产生的分配不均衡问题;但是,如果消费组单纯订阅一个 Topic,下面三种基本的分配策略效果是一致的。
- RangeAssignor 作为默认分配器,以分区 ID 作为区间连续分配给消费者,基于该规则,在订阅多个分区数一致的 Topics 时,用户可以在消费者内实施 Topic 之间的 Join 关联操作。
其实现原理 —— 把余数分配出去,比如 5 分区 3 消费者,余数是 2,于是给 1、2 号消费者各多分配一个分区。 - 当用户不需要对多个 Topics 进行 Join 关联操作,RoundRobinAssignor 基于轮询的分配方法可以缓解 RangeAssignor 基于余数固定分配给前 N 个分区导致的分区堆积。
- StickyAssignor 玩法更高级,可以解决不同消费者订阅不同分区时,最大化实现平衡分配,具体实现暂未深究,挖坑待填。
以上三种在重平衡过程中都需要中断所有分区的消费,归属于 Eager 激进式重平衡协议;KIP-429 提出一种增量分配的协作式策略 CooperativeStickyAssignor,过程中仅需中断部分分区的消费。
重平衡协议
- Eager 激进式协议
- onJoinPrepare 方法中,Coordinataor 撤销所有消费者持有的 TopicPartition,中断消费。
- 发起 JoinGroupRequest 请求,选出作为 Group Leader 的消费者,并告知其构建出每个成员消费的具体 TopicPartition 集合提议。
- Group Leader 通过 SyncGroupRequest 请求把提议告知 Coordinataor,并最终由 Coordinataor 返回给所有消费者,消费者客户端得到所属的 TopicPartition 集合后恢复消费。
- Cooperative 协作式协议
- 与激进算法的第一步不同,协作算法的第一步目标是让消费者感知到需要移除的 TopicPartition。其过程与上面 Eager 协议的二三步一样,但在特别之处是提议中删除了那些需要执行迁移到其他 Consumer 的 TopicPartition 集合。
- 消费者对当前分配的与提议的集合求差集,感知到需要移除的分区(即下线需要迁移的分区),移除完成后再次执行新一轮重平衡。
- 巧妙之处,与第一步一样,但是这时没有需要迁移的分区了(没有消费者持有过多的 TopicPartition),因此提议是完整的。
- 消费者收到新的提议后,assign API 上线缺失的 TopicPartition 即可(即上线需要迁移的分区)。
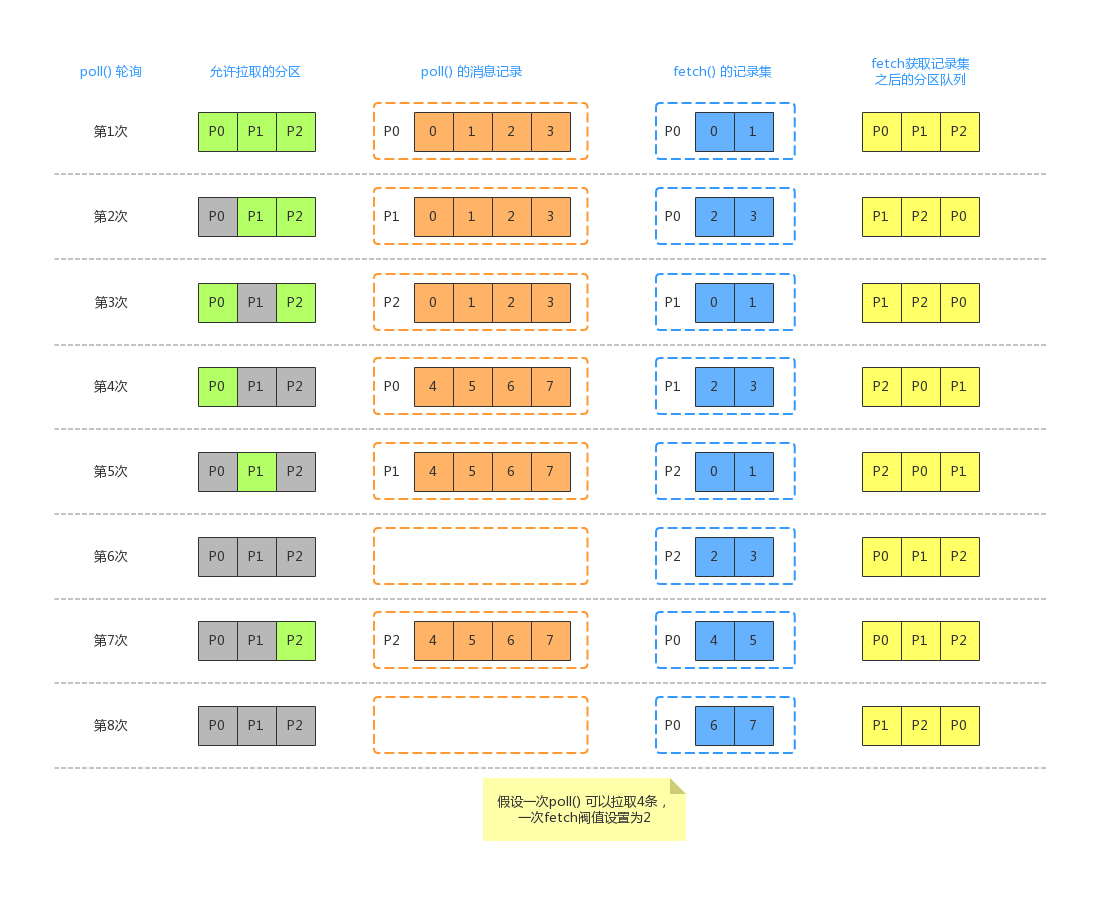
数据拉取消费实现
- 网络请求,允许拉取的 TopicPartition,只有非正在请求且非已拉取待处理的及正在处理的。
- 接收到数据后,会把结果(RecordSet)放在 completedFetches 队列里。
- 用户调用 poll API 时,若当前 completedFetches 队列里存在已完成的拉取,则每次从中读取最多至
max.poll.records的 Records。
图摘自参考资料二的文章,挺漂亮的。他假设了 max.poll.records=2 且 max.partition.fetch.bytes 的设置刚好对应返回 4 条数据(事实上,max.partition.fetch.bytes 拉取的数据末尾可能包含另一消息批的数据,会忽略,不影响使用),图示意的流程其实与上文一致。
可中断的分区 Reassignment 设计
术语
| 名词 | 解释 |
| RS | Current Replica Set,某分区在当前处于中间状态的副本集 |
| ORS | Original Replica Set,某分区未经历重分配之前的副本集 |
| TRS | Target Replica Set,某分区的重分配目标副本集 |
| AR | Adding Replicas,重分配过程新增的副本 |
| RR | Removing Replicas,重分配过程移除的多余副本 |
流程
首先,计算与记录 RS 、AR、RR,称为阶段 U;然后,执行重分配的两个阶段,分别是,A 阶段把 ORS 和 TRS 全部转换为 ISR, B 阶段转移 Leader 与删除 RR。
可中断的原理是,A 阶段由于是从分区起始数据同步,此过程可能非常慢,因此可中断的设计是针对未完成的 A 阶段,此时只要把 A 阶段的 TRS 置换为之前的 ORS,由于 ORS 本身就是 ISR,直接进入 B 阶段,进行转移 Leader 与删除 RR。

参考资料
- https://github.com/apache/kafka/tree/2.8
- http://moguhu.com/article/detail?articleId=138
- https://segmentfault.com/a/1190000039768128
- https://chrzaszcz.dev/2019/06/kafka-rebalancing/
- https://segmentfault.com/a/1190000040792326
- https://stackoverflow.com/questions/63867811/does-kafka-rebalancing-algorithm-balance-across-topics
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-497%3A+Add+inter-broker+API+to+alter+ISR
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-236%3A+Interruptible+Partition+Reassignment