Raft 分布式一致性协议笔记
Raft 是一种用来管理日志复制一致性算法。
基本概念
算法限定每个 Server 只能为以下三种状态之一:Leader、Follower 和 Candidate。
算法通过强化 Leader 地位简化日志副本的管理,比如日志项只允许从 Leader 流向 Follower。
因此 Raft 把算法分解为三个子问题:
- 选主(Leader Election)
- 日志复制(Log Replication)
- 安全性保障(Safety):前两个问题独立解决 OK,但是整合在一起还需要注意一些问题。
算法将时间分为多个 Term,Term 以单调递增连续整数标识,Term 值代表着 Leader 的任期号,Term 值的生命周期由每次 Leader Election 开始。如果有 Server 被选为 Leader,则该 Term 直到该 Server 结束 Leader 状态。
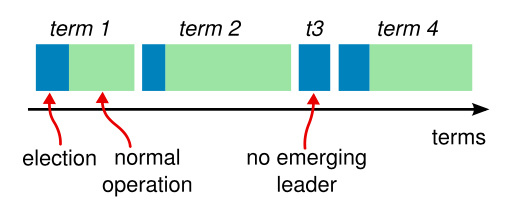
每个 Server 都维护着一个当前的 Term,Server 之间的所有的 RPC 都附带当前 Term 信息。
当 Server 接收到有效的 RPC 消息时,Server 会更新其自身记录中的 Term 值,当 Leader 或 Candidate 发现它们自身记录的 Term 属于旧的值,那么它们将会转成 Follower。
选主算法
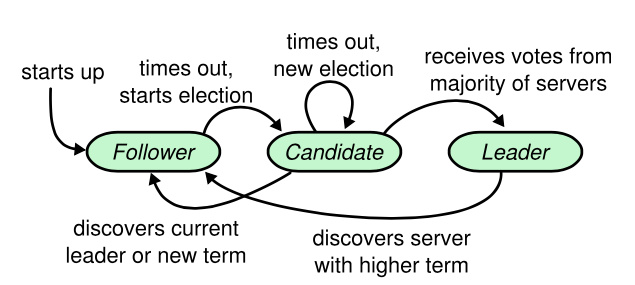
Raft 使用心跳机制来触发 Leader 选举。当 Server 启动时,默认 Follower 状态。当 Server 在超时时间内接受到由 Leader 或 Candidate 发出的有效 RPC,比如接收到 Leader 发出的 AppendEntry 报文和 Candidate 发出的 RequstVote 报文,就一直保持 Follower 状态。但如果超时时间内没有接受到任何消息,它就假设系统中没有可用的 Leader,转移到 Candidate 状态进行选举操作。
要开始一次选举过程,Follower 先增加自己的当前 Term 并转换到 Candidate 状态,然后投票给自己并向集群的其他 Server 调用 RequstVote RPC:如果远程 Server 的 Term < Candidate 的 Term,给它投票。Candidate 会一直保持当前状态直到以下三件事之一发生:
- 自己成为 Leader(收到过半数的投票)。
- 别人成为 Leader(收到比它 Term 值大的 AppendEntry)。
- 一段时间后没有任何获胜者,倒计时后再次重新选举(即,前两事件都没有发生)。
日志复制
正常的日志结构:
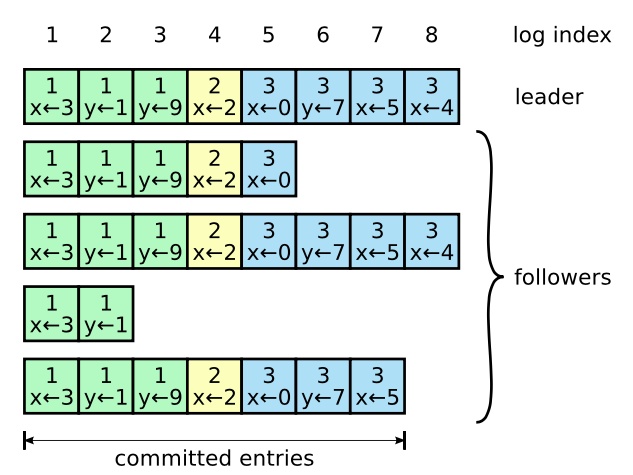
Raft 通过维护以下特性,构成日志匹配特性 ——
- 如果不同日志中的两个条目拥有相同的 Index 和 Term,即,
- 它们存储了相同的指令。
- 它们之前的所有日志条目也都相同。
Raft 在 RPC 中定义 NextIndex 变量,表示 Follower 想从 Leader 获取的下一条日志项 Index,即描述 Follower 当前偏移量,从而实现日志复制的进度同步。
由于算法限制日志项只能由 Leader 流向 Follower,所以这里只有两种情况:
- 复制成功,应用到状态机,Leader 统计回复结果并更新 CommitIndex。
- 复制失败。
由于可能存在网络延迟或分区导致日志复制失败,出现日志不一致,而不一致的内容需要删除或覆盖,因此,Raft 在 RPC 定义 PrevLogTerm、PervLogIndex 变量,代表日志内容的前一条 Term 及 Index,目的是告知 Leader,Follower 可能前一条日志项与当前 Leader 日志不一致(即,Term 或者 Index 不一样),那 Leader 将把前面的日志强制同步给该 Follower。
安全性保障
选举限制
基本算法存在的问题:选举时候对 Leader 日志没有进行判断,导致选出的 Leader 可能是日志尚未完整复制的少部分 Server。
解决办法:选举时候判对 Candidate 日志有没有比自己新,没有的话拒绝该 Candidate。
// Test if satify election restriction
canUpdateLogs := in.LastLogTerm > s.getLastTerm() ||
(in.LastLogTerm == s.getLastTerm() && in.LastLogIndex >= s.getLastIndex())提交之前任期的日志项
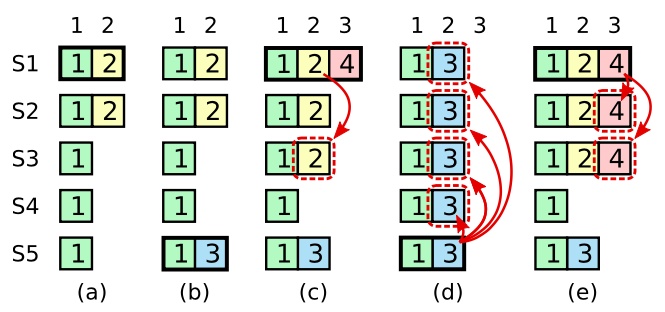
基本算法存在的问题:图片里有两个故事
- 故事1 [a, b, c, d]:由于图 a 的身份为 Leader 的 S1 崩溃,导致 Term:2 的日志只复制了两份;然后如图b,S5 被选为 Leader 并添加 Term:3 的日志,但是随后 S5 崩溃;然后如图 c,S1 连上并且被选为 Leader,并开始把 Term:2 的日志复制到 S3,可以看出 Term:2 的日志已经存在于大多数的 Server,但此时 Term:2 日志不能认为已被安全提交,因为存在如图 d 的情况,S1 又崩溃了,S5 又被选为 Leader(投票来自 S2、S3、S4 和自身 S5),这时候 S5 将复制其日志到所有 Server。
- 故事2 [a, b, c, e]:由于图 a 的身份为 Leader 的 S1 崩溃,导致 Term:2 的日志只复制了两份;然后如图 b,S5 被选为 Leader 并添加 Term:3 的日志,但是随后 S5 崩溃;然后如图 c,S1 连上并且被选为 Leader,并开始把 Term:2 的日志复制到 S3,可以看出 Term:2 的日志已经存在于大多数的 Server,但这次 S1 活的久了一点,把 Term:4 的日志也复制到大多数 Server,如图 e,这时候如果 S1 崩溃,S5 将不会被选为 Leader,因为 S5 所持有的最新日志是 Term:3,而当前大多数 Server 所持有的最新日志是 Term:4。
因此问题总结为:当某日志已复制到大多数 Server 中,但却不能保证该日志以后不被覆盖,因此日志不能认为被安全提交。
解决思路:Raft 为了简化算法,并没有杜绝这个现象出现,而是在日志能否被安全提交的判断上下文章。
解决办法:在以前判断能否被安全提交的条件是日志存在大部分 Server 的条件上,添加约束——该日志必须为当前 Term 产生的日志。
安全性论证
目的为了证明 Leader 完全特性:当 Leader 在其 Term 内提交了一条日志项,在往后的其他 Leader 和 Term 都存在这条日志项。
Raft 论文里面进行逆向推理,假设往后的其他 Leader 和 Term 都不存在这条日志项。
首先,要使往后的 Leader 不存在这条日志项,那么,
- 选举前不存在。
- 选举前存在,在任期内被删除或覆盖。
分别讨论,
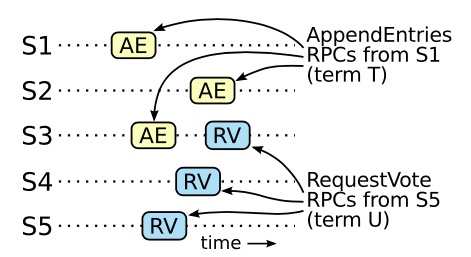
- 如上图,假设 S1 在 Term T(T<U)时刻把该日志项复制到 S2、S3,随后在 Term U 时刻,S5 成为新的 Leader,但这是不可能的。因为 S5 要获得大多数的选票,势必要从 S1、S2 或 S3 中一个获取选票,但是由于 S1、S2 或 S3 日志比 S5 更为新,它们都不会投票给 S5。所以选举前不存在这条日志项的 S5,永远也无法成为 Leader。
- 选举后在任期内被删除或覆盖,显然不可能,因为 Leader 不会删除或覆盖日志。
集群成员变更
成员变更本质上是集群配置的变更,可视作一种日志项。
安全的集群配置变更,首要条件是 —— 不能在变更过程中,选出两个 Leader,但实际上,如果采用从旧配置直接切换到新配置的方案,集群在调整过程中可能会分化为两个互斥的过半集合。
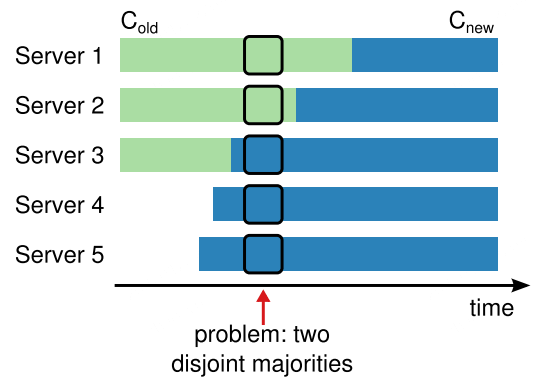
如上图的时间点,持有 $\rm C_{old}$ 配置的 S1、S2 感知不到新增的 S4、S5,认为当前集群节点数是 3,因此 S1、S2 可以满足过半数的选票而选举出 Leader(相当于认为 S3 宕机),S3、S4、S5 则采用了 $\rm C_{new}$ 配置,因此也可以满足过半数的选票而选举出 Leader(相当于认为 S1、S2 宕机)。
可见,直接切换是不可取的,于是,论文贴心地提出了解决办法 —— 联合共识。
联合共识把切换过程的 Server 描述为 3 种日志项,
- 日志项 $\rm C_{old}$,表示某 Server 处于旧配置。
- 一旦 Leader 收到 $\rm C_{new}$ 日志项,构建 $\rm \{C_{old}, C_{new}\}$ 日志,即 $\rm C_{old,new}$,应用并复制。
- 日志项 $\rm C_{old,new}$,表示某 Server 持有旧配置与新配置,并且在交替之中。
- 一旦 Leader 收到过半数的来自前持有 $\rm C_{old}$ 的复制确认(此时,Leader 本身是 $\rm C_{old}$),以及,过半数的来自前持有 $\rm C_{new}$ 的复制确认,视为 $\rm C_{old,new}$ 已提交。
- 当集群状态未满足成功提交 $\rm C_{old,new}$ 时,可以回到 $\rm C_{old}$ 的 Servers 中选举出新 Leader。
- 当集群状态满足成功提交 $\rm C_{old,new}$ 后,发生一次 Failover,此时整个集群发起投票, 会发现只有在持有 $\rm C_{old,new}$ 的 Server 选为 Leader。
(最坏情况只能一次 Failover,否则依据投票可能无法选出 Leader)
(比如,5 台 Old Server + 4 台 New Server,Leader 宕机,投票结果是 2 + 3)
(同上,假设,Leader + 1 New Server 宕机,投票结果是 2 + 2,可能无法选出 Leader)
- 日志项 $\rm C_{new}$,表示某 Server 处于新配置。
- 一旦 Leader 满足 $\rm C_{old,new}$ 已提交状态,切换至 $\rm C_{new}$,应用并复制。
- 一旦 Leader 收到过半数的当前持有 $\rm C_{new}$ 的复制确认,完成 $\rm C_{new}$ 的提交。将来的 Leader Failover 会由持有 $\rm C_{new}$ 的 Servers 选出。
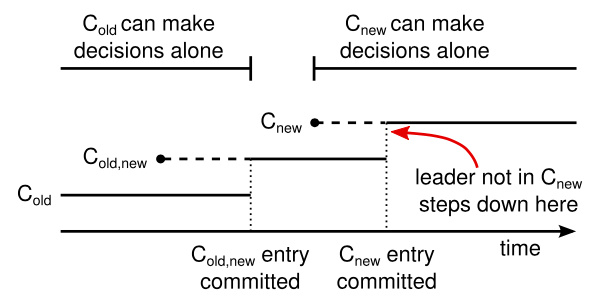
上图,实线部分视为配置已提交时刻,虚线部分代表未提交时刻。持有 $\rm C_{old}$ 日志项的 Servers 集合,在 $\rm C_{old,new}$ 日志项提交之前,Failover 后的 Leader 将会选举自 $\rm C_{old}$。$\rm C_{new}$ 同理。
另外,论文还提及需要注意的三个问题,
- 新增节点可能无任何日志。由于 Raft 对日志顺序性的严格要求,空日志或者落后的节点,实际上是不能立即提供服务的,但享有投票权。解决思路是新增节点标识为不具投票权的从节点,直到追上日志复制进度。
- Leader 可能不是新配置中的一员。还是投票权的问题,解决办法是 $\rm C_{old,new}$ 确认提交时,把当前排除在持有 $\rm C_{old}$ 的过半数统计逻辑中。
- 被移除的旧节点可能会扰乱集群。被移除的旧节点不计算在集群内,因此无法维护与集群其他节点的心跳,于是旧节点会推进 Term 并发起 RequestVote 请求申请成为 Leader。这行为将会扰乱集群,论文提供的解决办法是当已知 Leader 存活且持续心跳情况下,忽略不合理的 RequestVote 请求。
Go 语言描述
纯基本实现:https://github.com/akiasprin/kraft
实现备注:
applyChan 以无缓存 Channel 暴露给状态机,把日志的命令导出到状态机,由此实现分布式 KV 储存系统等,但问题该怎么设计 KV 查询的负载均衡?这是个疑问。
完整的添加日志设计应该是:新建 LogEntry{} 并返回它的 Term 和 Index,轮询 Leader 的 CommitIndex,如果 Index <= CommitIndex,比对 Logs[Index].Term == Term,因此添加日志有三种结果:提交成功、过期提交(Log[Index].Term != Term)、未提交(结果未知,需要不断提交直至出现前面确定的两种情况)。
参考资料
- https://raft.github.io/raft.pdf
- https://github.com/verg/MIT6.824_Labs
- https://github.com/goraft/raft
- https://www.zhihu.com/question/65667634
- https://blog.openacid.com/distributed/raft-bug/
- https://groups.google.com/g/raft-dev/c/t4xj6dJTP6E (旧论文提供两种成员变更处理方法,Single-Server-Change 单步变更和 Joint consensus 多节点联合共识,漏洞出现在单步变更,原因是选举时,基于旧配置的 Candidate 错误认为已过半数,修复方法很简单,成为 Leader 后提交一个空日志,然后因为该空日志的 Index 比使用了新配置的 Leader 写入的 Index 低,因此将被覆盖,就好像提交任期前的日志一样)