数据仓库维度建模笔记
维度建模模型本质是对关系模型的修补,提出缓慢变化维度的处理方案,使其更适用于记录历史数据,同时提出一致性理论,使得新的业务也可以从数仓总线中复用原有的数据。
数据仓库的建模第一步与关系建模过程一样,从业务过程开始分析,关系模型关注业务过程所需的字段,而服务于分析系统的维度建模,在此基础上还需要关心分析需求的指标(推动埋点的设计);然后构建总线矩阵梳理出原子粒度的维度表与事实表,生成 DWD 层明细表,最后由查询分析需求推动生成上卷汇总粒度的 DWS 层汇总表。
Kimball 维度建模架构
建模流程
- 数据调研
- 业务调研(竞争性商业问题、决策制定过程、支持分析需求的指标)
- 需求分析(关键性能指标)
- 维度建模设计与研讨
- 选择业务过程,业务过程是通过组织完成的操作型活动(或者叫事件),例如,获得订单、处理保险索赔、学生课程注册或者每个月每个账单的快照,活动行为将转化为事实表的事实。 (每个业务过程对应企业数据仓库总线矩阵的一行)
- 声明粒度,原子粒度是基础,上卷汇总粒度以优化性能。
- 确认维度,维度提供某一业务过程事件所涉及的背景;维度表应包含 BI 所需要的用于过滤及分类事实的描述性属性。(每个维度对应企业数据仓库总线矩阵的一列)
- 确认事实,事实表应描述业务过程中物理可观察的事件。
数据仓库总线架构
业务过程都会共用一些维度,形成了企业数据仓库的总线,一致化维度和事实看作一组标准的应用程序连接口,可以看作一个数据仓库的总线架构。当有新的业务过程引入数据仓库中,该业务过程可以从总线直接复用一致性的数据。
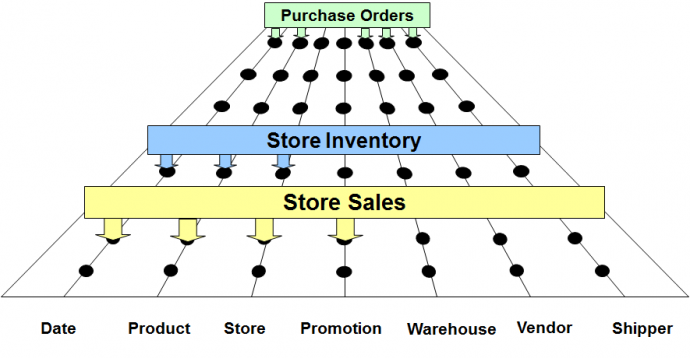
企业数据仓库总线矩阵,矩阵的行表示业务过程,列表示维度。矩阵中的点表示维度与给定的业务过程是否存在关联关系。 设计小组分析每一行,用于测试是否为业务过程定义好相关的候选维度,同时也能分析每个列,考虑某一维度需要跨多个业务过程并保持一致。
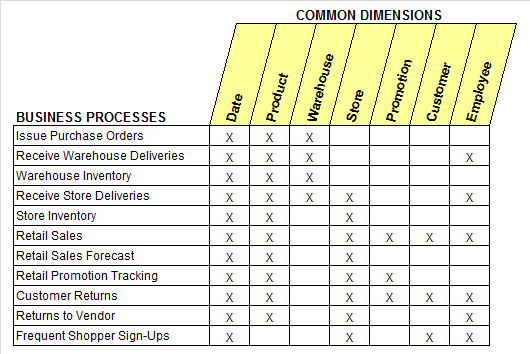
企业数据仓库总线矩阵是 DW/BI 系统的一个总体数据架构,提供了一种可用于分解企业数据仓库规划任务的合理方法,开发团队可以独立的,异步的完成矩阵的各个业务过程,迭代地去建立一个集成的企业数据仓库。
技术基础
事实表技术基础
事实表结构,事实表应该有数字指标、与维度表关联的外键、也可包含退化维度键和日期。
一致性事实概念,如果相同指标出现不同的事实表,那么要保证计算过程是一致的;同理,相同计算过程的事实表应该同名。
事实表类型,
- 事务性事实表,原子粒度。
- 周期性快照事实表,周期汇总。
- 累积性快照事实表,累积汇总。
- 无事实的事实表,仅描述事件,不包含可供分析的直接指标,但可表达关联性(其实是隐藏了连通关系的指标值)。
维度表技术基础
维度表结构 ,维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。 维度表属性是查询及 BI 应用的约束和分组定义的主要目标。 报表的描述性标识通常是维度表属性的领域值。
维度代理键,数据仓库内部维护的从值 1 开始的主键,目的是解决多业务系统数据源的主键冲突问题(比如不同产品业务内部用户表,可能遇到用户主键冲突)。 日期维度不需遵循代理键规则。
自然键、持久键、超自然键,自然键是业务系统自身规则生成的主键,自然键可能不具有持久性(比如雇员辞职再入职时,可能雇员编号就会发生变更),持久键就是实现包含描述状态变换(也就是未来雇员再入职时,只用修改其状态)。
退化维度,维度除了主键之外没有其他内容。通常会把退化维度直接放在事实表。
维度表类型,
- 日历日期维度,可不使用维度代理键,直接以 yyyyMMdd 表示。
- 扮演角色维度,自身与其他表之间有多重有效关系的表。这是维度中最常见的维度。
例如,基于键 Order Day、Ship Day 和 Close Day,Sales fact 与 Time 存在多重关系。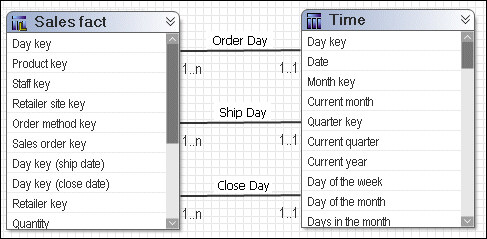
- 支架维度(Outrigger Dimensions),一个维度表引用其他维度表,形成雪花模型。支架维度可以减少数据重复存储,以及更新维护的复杂度,但可能会在查询时候创造很多麻烦。
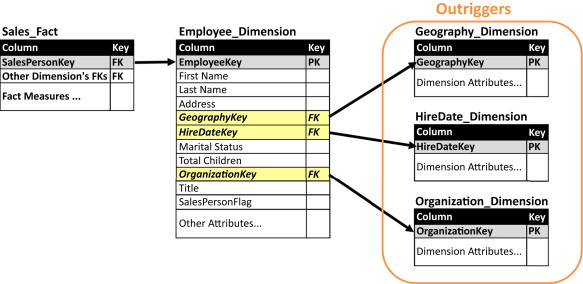
- 桥接维度,维度或者维度与事实表之间存在多对多关系,就需要建立多值桥接表。桥接维度可能也是缓慢变化维度。
- 层次维度(Hierarchical Dimensions),维度表是有层次结构的,可以邻接表 Adjacency List 方式构建。相比较,关系模型的层次结构实现玩法更多,可参考:Models for hierarchical data。
- 缓慢变化维度,
- TYPE 0、1,忽略或覆盖。
- TYPE 2,拉链表(还有个叫法是 SQL:2011 的 Temporal Table 历史表)。
在表结构中需要新增三个格外列:行起始日期列、行截止日期列、当前行有效性标识。
由于更新仅涉及上一版本与当前版的数据,所以大型拉链表可分多分区,定期可把多版本的数据清到新的归档分区里,减少 ETL 运算量,全量获取也只需 Union 一下。
- TYPE 3,增加新的历史列,并改写标识当前状态的列(相对少见,但是对于 TYPE 2 的拉链表,在查询所有历史状态时候减少了 Group by 或者 Window 计算)。
- TYPE 4,增加微型维度(Mini Dimensions)。
微型维度的提出主要是为了解决快变超大维度(Rapidly changing Monster Dimensions)。 以客户维度举例来说,如果维度表中有数百万行记录或者还要多,而且这些记录中的字段又经常变化,这样的维度表一般称之为快变超大维度。对于快变超大维度,设计人员一般不会使用拉链表的缓慢变化维处理方法(TYPE 5),因为大家都不愿意向本来就有几百万行的维度表中添加更多的行。 这时,可将分析频率比较高或者变化频率比较大的字段提取出来,建立一个单独的维度表,事实表通过 Profile Key 关联微型维度表。这个单独的维度表就是微型维度表。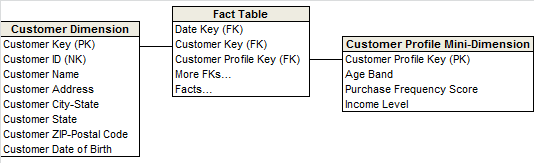
- TYPE 5 混合双打,增加微型维度及支架(视图)维度。
当 TYPE 4 的 Profile Key 放在维度表时,那就相当于关联了微型维度表作为支架维度,这使得维度表的描述重新包含了 TYPE 4 抽取出来的字段(TYPE 4 中维度表中是无法得知抽取出来的字段状态,需要关联事实表才能查询出来)。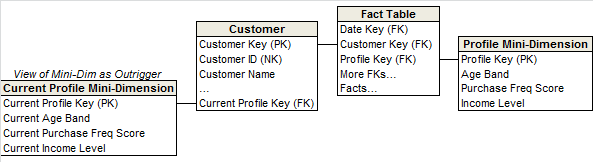
- TYPE 6 混合双打,TYPE 2 拉链表 + TYPE 3 历史列,便于直接查询上一个状态。
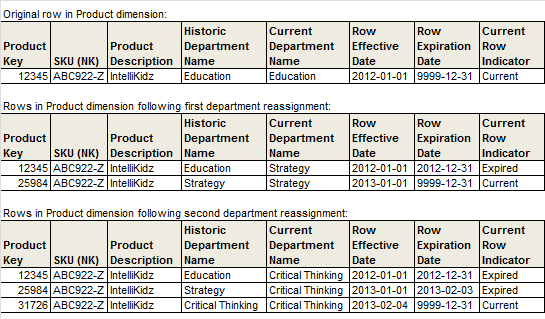
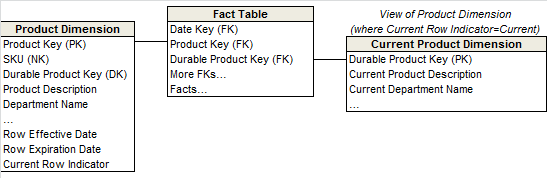
- TYPE 7 混合双打,TYPE 7 效果与 TYPE 6 是一样的,只是把历史列的值改成维表的外键,然后使用视图进行关联。因为记录的是外键,相比较于单一或者有限状态,相对来说会灵活一些,但是查询时候复杂度也会高一些。
阿里集团 OneData 维度建模架构
阿里《大数据实践》的思想比较具体,但笔者我并无实战经验,日后有机会配合实际情况再接着讨论。
建模流程

分层概念

OneModel 模型
OneModel 以维度建模为理论基础,划分和定义业务板块、数据域、业务过程、维度、度量/原子指标、业务限定、时间周期、派生指标,设计出维度表、明细事实表、汇总事实表的过程。

OneModel 的一个核心内容是派生指标的构建方法。在 OneModel 中,派生指标由原子指标、时间周期、业务限定、统计粒度统一定义。
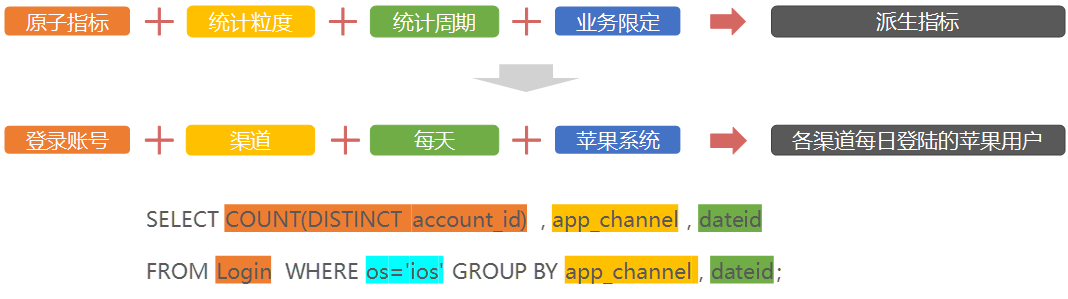
命名规范
ODS
表命名规则:s_{源系统表名}{保留位/delta与否}
- 增量数据:{project_name}.s_{源系统表名}_delta。
- 全量数据:{project_name}.s_{源系统表名}。
- ODS ETL过程的临时表:{project_name}.tmp_{临时表所在过程的输出表}{从0开始的序号}。
- 按小时同步的增量表:{project_name}.s_{源系统表名}_delta_hh。
- 按小时同步的全量表:{project_name}.s_{源系统表名}_hh。
表存储方式
- 增量快照存储,普通流水型数据。
- 全量快照存储,对于小数据量的缓慢变化维度数据,例如商品类⽬,可直接使⽤全量存储。
- 全量拉链存储(极限存储),对于大型缓慢变化维度数据,可使用拉链存储。
- 不使用代理键(国内,直接拿个人身份证 ID 也就行了)。
DIM
表命名规范:dim_{业务板块名称/pub}_{维度定义}[_{自定义命名标签}]
- 公共区域维表:dim_pub_area
- A公司电商板块的商品全量表:dim_asale_itm
DWD
表命名规范:dwd_{业务板块/pub}{数据域缩写}{业务过程缩写}[{⾃定义表 命名标签缩写}] {单分区增量全量标识}
单分区增量全量标识为,i 表⽰增量,f 表⽰全量。
- A电商公司航旅机票订单下单事实表,⽇刷新增量:dwd_asale_trd_ordcrt_trip_di
- A电商商品快照事实表,⽇刷新全量:dwd_asale_itm_item_df
DWS
表命名规范:dws_{业务板块缩写/pub}{数据域缩写}{数据粒度缩写}[{⾃定义表 命名标签缩写}]{统计时间周期范围缩写}
- 关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近⼀天(_1d),最近N天(_nd)和历史截⾄当天(_td)三个表。如果出现 _nd 的表字段过多需要拆分时,只允许以⼀个统计周期单元作为原⼦拆分。即⼀个统计周期拆分⼀个表,例如最近7天(_1w)拆分⼀个表。不允许拆分出来的⼀个表存储多个统计周期。
- 对于小时表[⽆论是天刷新还是小时刷新],都⽤ _hh 来表⽰。
- 对于分钟表[⽆论是天刷新还是小时刷新],都⽤ _mm 来表⽰。
- A电商公司买家粒度交易分阶段付款⼀⽇汇总事实表:dws_asale_trd_byr_subpay_1d
- A电商公司买家粒度分阶段付款截⾄当⽇汇总表:dws_asale_trd_byr_subpay_td
- A电商公司买家粒度货到付款交易汇总事实表:dws_asale_trd_byr_cod_nd
- A电商公司卖家粒度商品截⾄当⽇存量汇总表:dws_asale_itm_slr_td
- A电商公司卖家粒度商品小时汇总表:dws_asale_itm_slr_hh
- A电商公司卖家粒度商品分钟汇总表:dws_asale_itm_slr_mm
参考资料
- https://www.kimballgroup.com/2013/02/design-tip-152-slowly-changing-dimension-types-0-4-5-6-7/
- https://en.wikipedia.org/wiki/Slowly_changing_dimension
- https://blog.csdn.net/weixin_32806343/article/details/112558116
- https://nlogn.art/wp-content/uploads/2021/05/Kimball_The-Data-Warehouse-Toolkit-3rd-Edition_%E4%B8%AD%E6%96%87%E7%89%88.pdf
- https://nlogn.art/wp-content/uploads/2021/05/Kimball_Data_Warehouse_ETL_Toolkit.pdf
- https://nlogn.art/wp-content/uploads/2021/05/MaxComputer_1%E6%9E%84%E5%BB%BA%E4%B8%8E%E4%BC%98%E5%8C%96%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93.pdf
- https://nlogn.art/wp-content/uploads/2021/06/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%8F%B0%E5%AE%9E%E8%B7%B5_2019.pdf
- https://xie.infoq.cn/article/b93875077c776fb0dc9d85858
棒!