决战八股文之巅
SQL
长宽表转换
# 长表转宽表
with t1 as (
select
id,
str_to_map(concat_ws(',', collect_set(concat_ws(':', k, v)))) as m
from t_narrow_dim
group by id
)
select
id,
m['name'] as name,
m['age'] as age,
...
from t1;
# 宽表转长表
with t1 as (
select
id,
map('name', name, 'age', age, ..) as m
from t_wide_dim
)
select
id,
explode(t1.m) as (k, v)
from t1;开窗
页面停留时间
MACD
UDF
Java
类加载
- 类加载过程
- 加载,将
.class文件读取到方法区(元空间) - 链接,主要处理符号引用,比如对其他类的引用
- 初始化,执行构造方法,分为
<init>与<clinit>,<init>是类的构造函数,<clinit>是初始化静态变量与静态代码块- ClassLoader.loadClass 是不会执行
<clinit> - Class.forName 会执行
<clinit>,因此它是 SQL Driver 加载的常见写法
- 加载,将
- 类加载器(从上到下)
- Boot. Classloader(rt.jar)、Ext. Classloader、App. Classloader
- 双亲委派
- 一种安全保护机制,防止核心的 Java 类被篡改,所有类加载请求都往上提交。
- 上向下破坏:Thread#getContextClassLoader。
可以理解,越上层的类加载器能加载的类越少,如何让运行在上层类加载器的线程获取到动态的自定义或者 App. 加载器呢?Thread#setContextClassLoader 提供可注入的地方。 - 下向上破坏:热更新。
在 App. 加载器之下再创建子加载器,检测到版本变更时,让新的线程用新的子加载器加载,得到不同线程运行相同类名但不同代码的形式。
多线程
- 背景 — JVM 内存模型规范(JMM 规范)
JMM 规范主要规定volatile与final修饰的共享变量在多线程编程下的可见性与有序性。- 可见性,使用 LOCK# 指令前缀,修改强制写回主存,并作废其他核心寄存器缓存
- 有序性,使用内存屏障禁止指令重排序
- 背景 — JVM 内存结构
- 堆(JDK 8 后,常量池迁移至堆中)
- JVM 栈帧(局部变量表、操作数栈、方法返回地址等等)
- 本地方法栈帧(JNI 不与 JVM 的共用)
- 元空间(方法区)
- 其他 — 线程池,ThreadPoolExecutor 的参数
IO
- ByteBuf/ByteBuffer
G1 GC
- 背景 — GC Root
- 由 Boot. 加载器加载的类,及类的静态变量。
- 栈帧中的局部变量表。
- 存活的 Java 线程。
- JNI 引用的对象。
- 等等(比如 Busy Monitor,MAT 中会具体表明)。
- 背景 — 三色标记
三色代表着三种集合,主要用于辅助问题分析,- 白色代表辣鸡
- 黑色代表有效对象,且该对象引用的子对象集合已经被染色
- 灰色代表该对象引用的子对象集合暂未完全染色,最终将转为黑色
- 背景 — 分区
- 对堆进行分区,一般固定 2K 个 Regions,每个区最少 1M 最多 32M
- 当堆大小超过 2K * 32M 时候,向上扩张 Region 数。
- 背景 — Collection Set
CSet 记录当次 G1 GC 需要回收的 Regions,相当于 GC 的工作目标。 - 背景 — Card Table 与 Remember Set
- Card Table 是位图结构,每一位(也称为 Card Page)代表着 512B 的堆空间,主要是用来标记在 Concurrent Mark 阶段时,若存在黑色对象引用变更,将把对象在 Card Table 的 Page 标记为 Dirty,在未来 Remark 阶段,重新分析 Dirty 对象引用链路,重新染色。
- Remember Set 是 HashMap<Region, List<Card Page>> 结构,每一个 Region 都持有一个 RSet 结构,其代表其他 Regions 对当前 Region 的引用关系,通过 RSet,即便不用扫描所有 Region,也可以知道当前 Region 的对象有哪些被引用(即 Point-into 的信息)。
- YGC
- YGC 触发在 Eden 区写满。通过 GC Root 进行搜索,把检索到处于新生代的对象,复制到 Survive 区,对于超过 15 次的 YGC 中存活,则复制到 Old 区。
- 由于 YGC 是需要过滤掉老年代中对新生代的引用,实际是使用 GC Root + RSet 平铺结构辅助搜索,就可以避免对单纯基于 GC Root 时需要对老年代 Region 的内部复杂检索。
- Mixed GC
- 与 YGC 的 标记复制 算法不一样,Mixed GC 对老年代采用 标记清理 算法,分为 4 步,
- initial Mark,STAB + 展开与标记 GC Root 的第一层对象
- concurrent Mark,并行标记其余对象
- Remark,对于 concurrent Mark 过程中变更的对象引用重新标记
- Clean-up,清理
- 与 YGC 相似,Mixed GC 也需要过滤不关联的 Old 区(也就是不在 CSet 的),同样的,利用 RSet 结构可以忽略掉不关联的 Old 区细节。
- 与 YGC 的 标记复制 算法不一样,Mixed GC 对老年代采用 标记清理 算法,分为 4 步,
- 深入 — 三色标记异常情况分析与 STAB 作用
- STAB(Snapshot-At-the-Beginning)机制:
通过 Hook 在对象引用变更时,既保留原始引用关系,也保留变更后的引用关系。
- 这里面太复杂了,暂时没有时间展开研究了。
- STAB(Snapshot-At-the-Beginning)机制:
- 其他 — 建议阅读美团技术团队的关于 G1 的文章3,写得真的很飘逸,但句句都是重点。
- 其他 — 默认新生代占 1/3,老年代占 2/3,Eden 区与 Survive 区占比 8:1:1,因此 Eden 区约占 26.66%。
Kafka
- Kafka 消费回压
- 我们消费模型是单线程消费,多线程异步处理(Vert.x)
因此设计为,- 定义 Msg = Pair<ConsumerRecord, completed 标记>;
- 消费时先进入 Map<PartitionId, PriorityBlockingQueue<Msg>> 结构;
(依 Msg 的 ConsumerRecord$offset 排序) - 处理业务模块;
- 当业务处理完成,标记已完成状态(completed=true);
- 当需要提交 Offsets 时,按分区分别处理,按顺序先 Drop 掉队列中处理完成的消息,得到第一个未提交的 Offset,这就是该分区可提交的 Offset。
- 回压,实现原理就是计算上面队列的存量数据,当存量大于阈值,则消费速率减半(也就是阻塞消费线程),当持续时间内,存量小于阈值,则消费四倍增大,直至等于阈值。
- 我们消费模型是单线程消费,多线程异步处理(Vert.x)
- 控制 Kafka 的传输速率
- 客户端,配置 ZK 中 Client/User Entity,Broker 计算批的流量的延时,以延迟响应。
- Broker 端,通常限制分区重分配时的复制速率,可以直接 reassign 命令中指定,其配置的是 ZK 中 Broker&Topic Entity,缺点是会影响正常生产消费。
# 对于匿名生产者消费者(未配置 client.id)速率限制为 20MB/s
kafka-configs.sh --alter \
--add-config 'producer_byte_rate=20971520,consumer_byte_rate=20971520' \
--entity-type clients \
--entity-default
# 对于分区重分配的复制速率限制为 100M/s
kafka-reassign-partitions.sh \
--reassignment-json-file reassignment-json-file.json \
--execute \
--throttle 104857600
# 上面等价于下面组合命令
# Leader 副本是数据源(代表着旧副本),Follow(代表着新副本)从 Leader 中获取
kafka-configs.sh --alter \
--add-config 'leader.replication.throttled.rate=104857600,follower.replication.throttled.rate=104857600' \
--entity-type brokers \
--entity-name 1
kafka-configs.sh --alter \
--add-config "leader.replication.throttled.replicas='0:0,0:1,1:1,1:0',follower.replication.throttled.replicas='1:2,0:2'" \
--entity-type topics \
--entity-name user_locationSpark
基本关系
- 一个 App 对应一个 SparkContext,由 SparkSession 创建
- App 内有多个 Jobs,每触发一次 sc#runJob 就会产生一个 Job
- Job 内有多个 Stages,Stage 是由 DAGScheduler 通过宽窄依赖划分,对应 Shuffle 过程
- Stage 内也有多个 Tasks,组成 TaskSet,由 TaskScheduler 把任务分发到 Executors
Spark Shuffle 对 Cache&Checkpoint RDD 的影响
相比较 MR Shuffle,Spark 的特点是 Map 端的 combine() 函数会通过 AppendOnlyMap 数据结构进行在线聚合,而不是当 map() 函数完成后,对已落地文件重新读取执行 combine() 函数。
这使得 C&C RDD 的设计变得复杂,因为 Map 端的 Shuffle Write 写出的结果将只适用于当前的算子(Shuffle Write 是执行了特定的 combine() 聚合函数的结果,而不是 RDD 本身的数据)。
- 对于 Cache RDD,Spark 在执行
combine()之前对每一条 record 执行persist() - 对于 Checkpoint RDD,Spark 采取不影响正常计算链路,重新计算实现
(因为 Checkpoint 写 HDFS 的延时可能影响正常计算,而 Cache 只写本地磁盘或内存)
Algorithm
- 求最大子矩阵和:枚举横轴两线,通过对列求和,降维到一维数组,在一维数组求子序列的最大和,得到其一维数组的两个端点,也即对应矩阵的两根纵轴。
- 数组均分问题:
- 二分两数组的中位数:由于中位数 M 是两数组总长度折半,因此二分枚举其中一个数组的位置 P,可得出另一数组的位置 Q = M – P,并使得 B[Q – 1] < A[P] 且 A[P – 1] < B[Q],然后再分辨 A[P] 或 B[Q] 是中位数。
- 两字符串的编辑距离:建立二维 DP,纵轴代表字符串 U,横轴代表字符串 V,可得转移方程,DP[i][j] = min(DP[i – 1][j] + 1, DP[j – 1][i] + 1, DP[i – 1][j – 1] + (U[i] != V[j]))。
- 股票买卖含冷冻期:建立两组二维 DP,一组是表示持仓的 held[2][i],另一组是表示空仓的 folded[2][i],每组分别有两种状态(共 4 种状态),
- 持仓的可能是昨天就持仓,今天维持该状态,也可能是空仓然后今天买入;
- 空仓的可能是昨天就空仓,今天也维持该状态,也可能昨天持仓,今天卖出。
Operation System
三次握手,很重要的一点就是同步初始的序列号。
半连接队列与全连接队列,存在于服务端,半连接可以理解已 Acked 客户端序列号,但由于未完整握手成功,未收到来自客户端的 Ack,也就是不知道客户端已 Acked 服务端的序列号;全连接就是收到来自客户端的 Ack,连接从半连接状态转移到全连接状态。
四次挥手,
- FIN_WAIT_1 对应关闭【客户端写出流】与等同含义的服务端读入流;
- FIN_WAIT_2 对应关闭【服务端写出流】与等同含义的客户端读入流;
- 上述两个状态,一来一回,构成四次挥手。
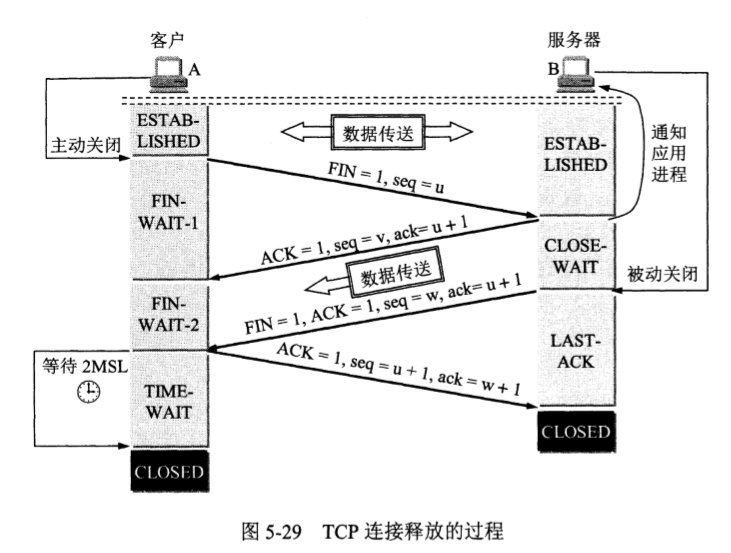
四次挥手结束时,TIME_WAIT 将等待 2x MSL 时间(Maximum Segment Lifetime 最大报文段时间,默认 2 分钟),以应对最后一次客户端发送 ACK FIN 时可能的丢失,一旦丢失且不存在 TIME_WAIT 时间,服务端重试后将收到 RST 信号,误以为客户端异常。
SO_REUSEADDR 参数,是让 TIME_WAIT 状态的 Socket 允许重用(如网关场景),理论上相当于把操作系统应对 ACK FIN 丢失的逻辑下放到用户应用程序上。
Spring Web & Spring Cloud
- Bean 的作用域有哪些?@Scope 有 Singleton 与 Prototype
- Bean 的生命周期是?
- Bean 的线程安全问题?ThreadLocal,事务就是用 ThreadLocal 传递上下文
- BeanFactory 和 ApplicationContext 有什么区别?
- 怎么解决循环依赖?延迟注入,具体细节是通过 L1、L2、L3 缓存实现。
L1 是已经装配完成的 Beans,L2 是实例已创建但未完成装配,L3 则是 Beans 工厂方法。 - 事务传播规则?父调用的事务传播到子调用(默认),或者创建新的事务,又或者并行调用时,优先执行非事务调用,让事务调用挂起。